1. Drawback of Seq2Seq Architecture
지난 시간 배웠던 Seq2Seq 아키텍처에서는 다음과 같은 문제가 있었다.
1. Encoder에서 Decoder로 넘겨주는 정보가 마지막 hidden state, 즉 하나의 임베딩 벡터 뿐이므로 문장이 길어질 수록 하나의 임베딩 벡터에 모든 정보를 다 잘 담기 어렵다는 문제가 발생한다. 이를 Information bottleneck 이라고 한다.
2. 또한 Encoder와 Decoder 사이의 상호작용이 없다. 전달하는 것은 Encoder에서 Decoder로 넘기는 임베딩 벡터 하나 뿐이다.
이러한 문제를 해결하기 위해 등장한 후속 연구가 Attention Mechanism 이다.
2. Attention Mechanism in Machine Translation
'Neural Machine Translation By Jointly Learning To Align And Translate'는 처음으로 attention 개념을 사용한 논문이다.
번역을 하는데, 번역 대상의 언어와, 목표 언어의 정합(align)을 같이 한다는 것이다.

1. 입력 시퀀스 임베딩
입력으로는 번역 대상이 되는 언어의 단어 시퀀스가 들어간다. 각 단어는 임베딩되어 순서대로 RNN 인코더에 들어가고, 각 시점마다 hidden state가 생성된다.
2. 디코더 초기화
인코더의 마지막 hidden state를 디코더의 초기 상태 s0로 사용한다. (s0 = h4)
3. Alignment Score 계산
디코더가 출력을 만들기 전에 입력 시퀀스에서 어떤 부분을 주목하는지 계산하기 위해 현재 디코더의 상태(St-1)과 인코더 hidden state 간의 유사도를 구하는 단계이다.
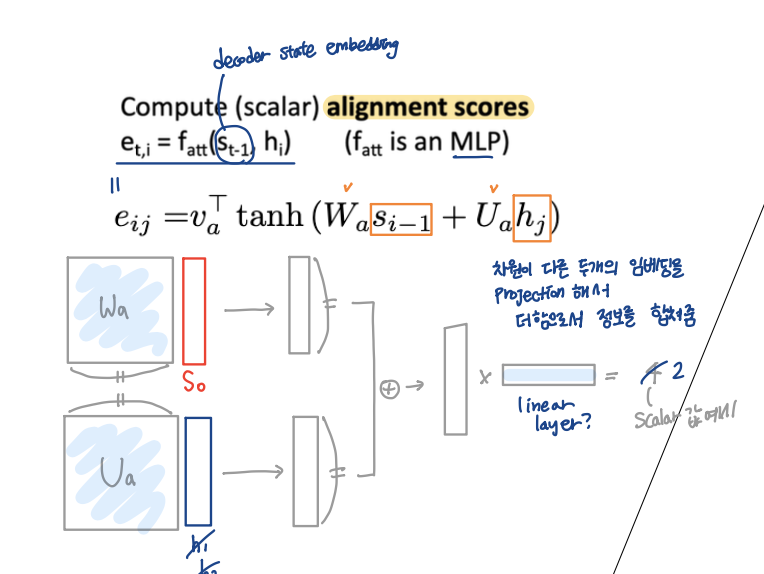
alignment 점수를 구하는 방식은 위 이미지의 식과 같다. s0는 각각의 hidden state와 Fatt연산을 해서 그 간의 유사도를 하나의 스칼라 수치로 표현한다. s0와 h의 유사도를 구하기 위해서는 s0와 h가 연산가능하도록 차원을 맞춰주기 위해 각각의 projection 연산이 들어가고, 이를 더한 후 스칼라 값으로 바꾸기 위한 벡터가 필요하다. 이 세 개는 learnable parameter!
(*MLP: Multi-Layer Perceptron, 여러 개의 선형층(Linear)+비선형함수(ex ReLU, tanh)가 여러 개 쌓인 구조)
| 파라미터 | 입력 | 출력 | 역할 | |
| Wₐ | sₜ₋₁ | Wₐ sₜ₋₁ ∈ ℝ^d_att | 디코더 state를 attention 계산에 적합한 차원으로 projection | 디코더 state → attention 공간 |
| Uₐ | hⱼ | Uₐ hⱼ ∈ ℝ^d_att | 인코더 state를 같은 attention 계산을 위한 차원 공간으로 projection | 인코더 state → attention 공간 |
| vₐᵀ | tanh(...) | eₜⱼ ∈ ℝ (스칼라) | attention 공간의 한 벡터를 scalar로 압축하는 projection 벡터 | attention 공간 → score 공간 |
4. Attention Score 계산
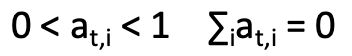
Alignment Score에 Softmax를 취해 Attention Score를 구한다.
5. Context Vector 생성

attention Score과 hidden state 각각을 가중합하여 Context vector를 생성한다. 이렇게 생성된 context vector는 디코더가 다음 출력을 위해 어느 단어에 집중해야하는지를 알려준다!
6. 디코더 상태 갱신

이전 출력 단어(Yt-1), 이전 디코더 상태(St-1) 그리고 추가적으로 Context vector까지 넣어서 디코더의 새로운 hidden state, S을 생성한다. 위 식에서 g_u는 디코더의 RNN 셀이다(LSTM)
7. 출력 단어 생성
디코더의 새로운 상태 S를 이용하여 단어 Y를 출력한다.
위 과정을 반복해서 Y1, Y2, Y3 ... 등 다음 단어들을 순차적으로 생성해 나간다.
context vector는 그 시점의 디코더 hidden state를 이용해 계산되므로 context vector는 매 시점마다 다르다(time-dependent attention) -> 따라서 Input Sequnece는 단일 임베딩 벡터로 병목현상이 생기지 않고, 매 시점마다 decoder는 context vector에 의해 input sequence의 다른 부분을 집중한다. 결국 임베딩 벡터 하나에 모든 정보를 다 넣어주는 문제, 상호작용이 없는 문제를 모두 해결한다.
또한 Attention은 직접 가르쳐주어 학습하는 것이 아닌, backpropagation으로 모델이 직접 학습한다.
3. Attention Mechanism in Image Captioning
멀티모달 Image Captioning Task에서도 동일한 문제점이 있었다. (Show and Tell)
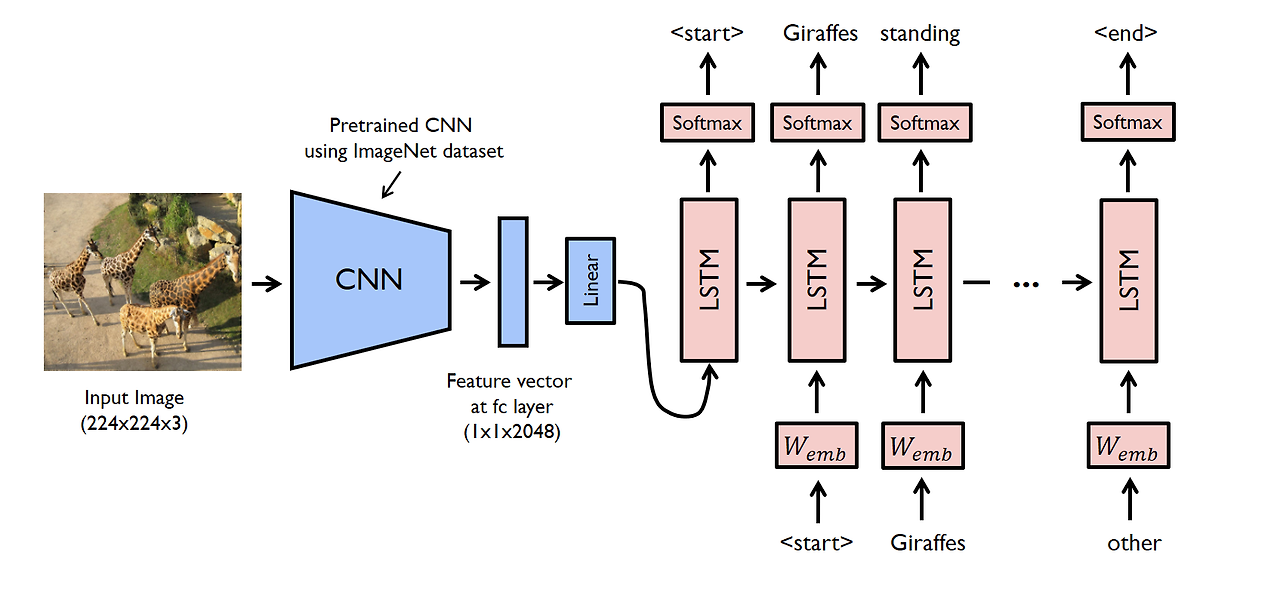
이게 show and tell의 구조인데, 여기서도 역시 Information bottleneck, Encoder와 Decoder 사이의 상호작용 없는 문제가 있다. 또 gap 다음의 flatten 된 벡터를 넘겨주니 그거는 이미 공간정보도 소실된 상태이다.
여기서 Attention 매커니즘을 적용한 시도가 Show, Attend and Tell 이다.
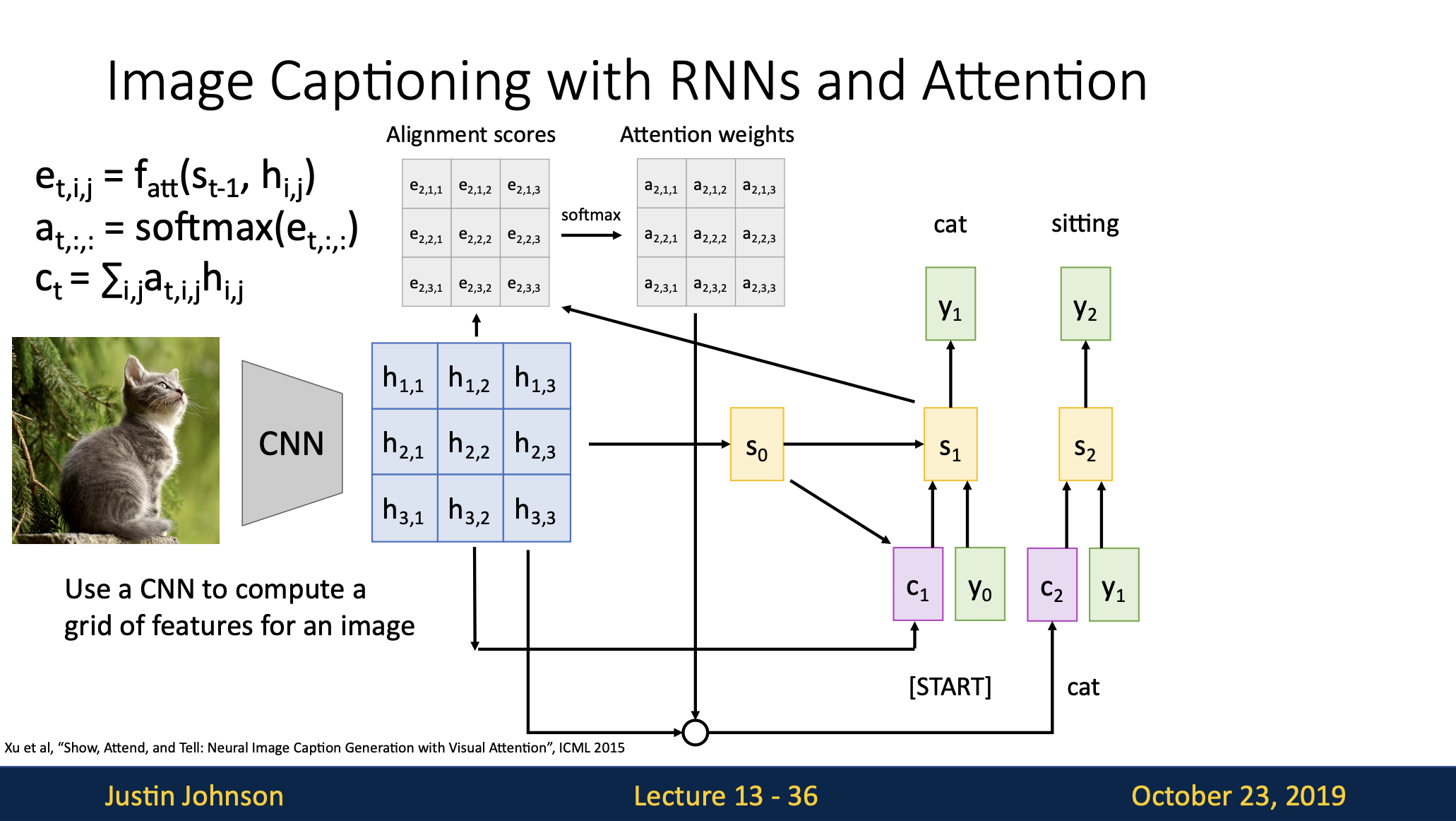
입력이 단어 Sequence에서 이미지로 바뀔 뿐 큰 구조는 동일하다!
위와 대응되게 단계별 설명을 써보겠다.
1. CNN으로 이미지 특징 추출
입력된 이미지가 CNN을 거쳐 Grid 형태의 Feature Map으로 Output이 나온다. CNN은 Conv Layer를 통과할수록 해상도가 작아지고 채널 수는 커지는데, 그 결과로 위 이미지에서는 3x3이 되었다. (채널은 Resnet50의 경우 2048이므로 3x3x2048형태이다)
이 부분이 인코더 역할을 한다.
2. 디코더 초기화
인코더 CNN의 Feature Map을 Global Average Pooling을 적용해서 디코더 RNN(LSTM)의 첫 hidden state S0를 초기화한다.
3. Alignment Score 계산
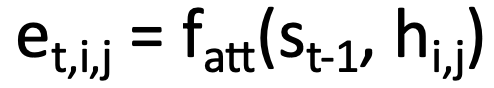
각각의 h(위 이미지에서는 총 9개)를 s와 f_att 연산해서 스칼라 값의 유사도를 구해준다.
4. Attention Score 계산

Alignment Score 값들에 Softmax를 취해 Attention Weigts를 구해준다.
5. Context Vector 생성
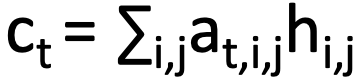
attention Score과 hidden state 각각을 가중합하여 Context vector를 생성한다. 이렇게 생성된 context vector는 디코더가 다음 출력을 위해 이미지의 어떤 부분에 집중해야하는지를 알려준다!
6. 디코더 상태 갱신
이전 출력 단어(Yt-1), 이전 디코더 상태(St-1) 그리고 추가적으로 Context vector까지 넣어서 디코더의 새로운 hidden state, S을 생성한다.
7. 출력 단어 생성
위 과정을 반복해서 이미지 기반 캡션을 한 단어씩 생성해나간다.
자료 출처
https://github.com/yunjey/pytorch-tutorial/tree/master/tutorials/03-advanced/image_captioning
'멀티모달인공지능' 카테고리의 다른 글
| CNN(Convolution Neural Network)이란 (0) | 2025.03.19 |
|---|