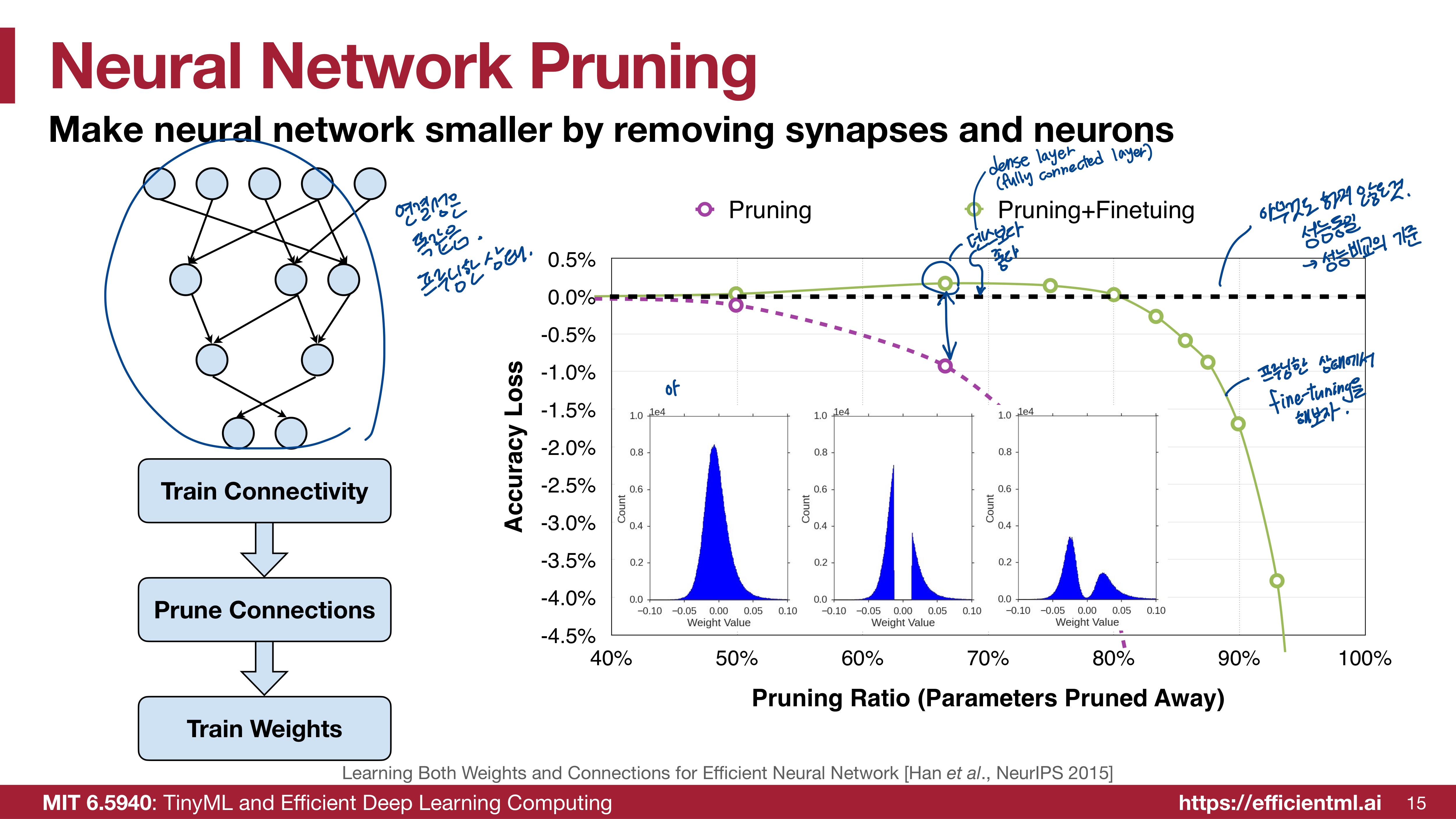
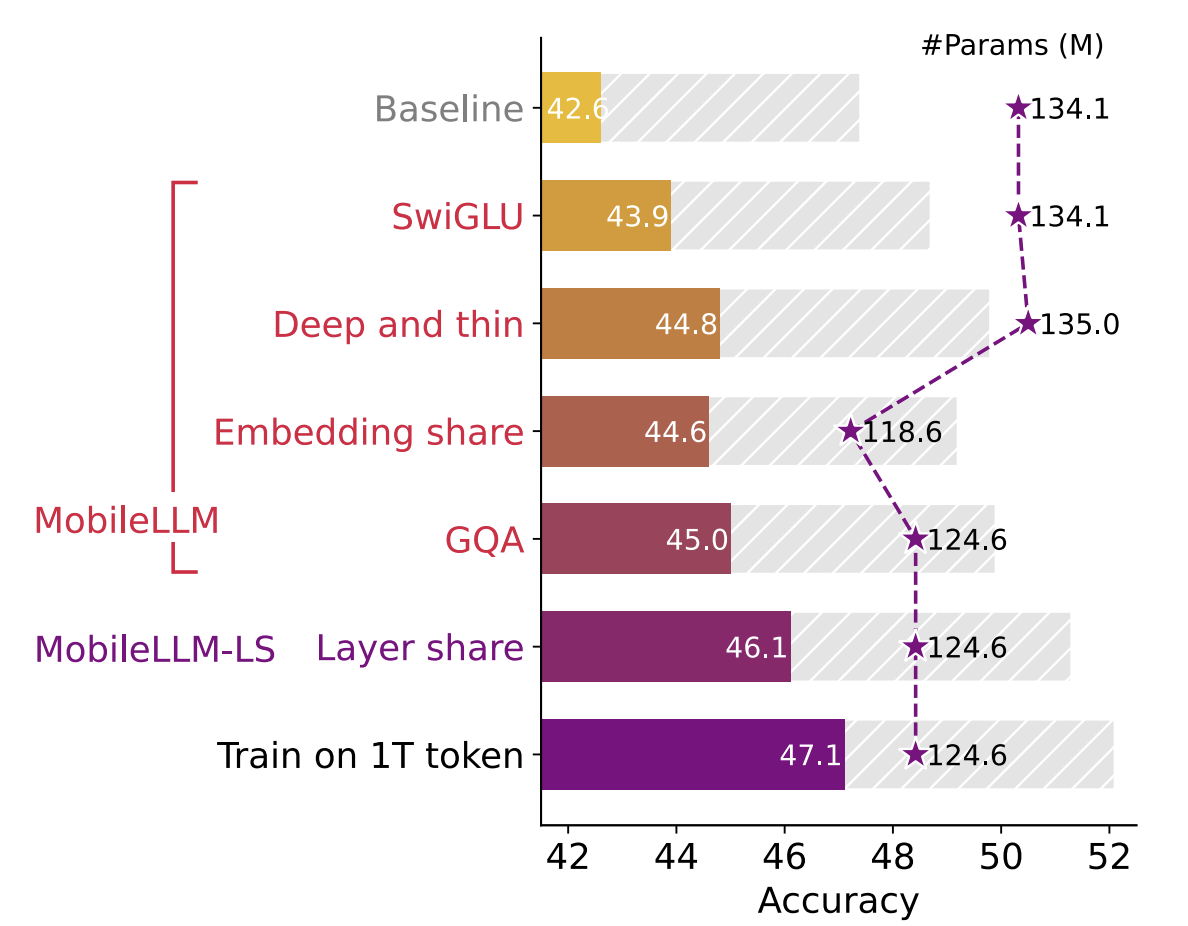
Li, S., Ning, X., Wang, L., Liu, T., Shi, X., Yan, S., ... & Wang, Y. (2024). Evaluating quantized large language models. arXiv preprint arXiv:2402.18158https://arxiv.org/abs/2402.18158 Evaluating Quantized Large Language ModelsPost-training quantization (PTQ) has emerged as a promising technique to reduce the cost of large language models (LLMs). Specifically, PTQ can effectively mitigate memor..