
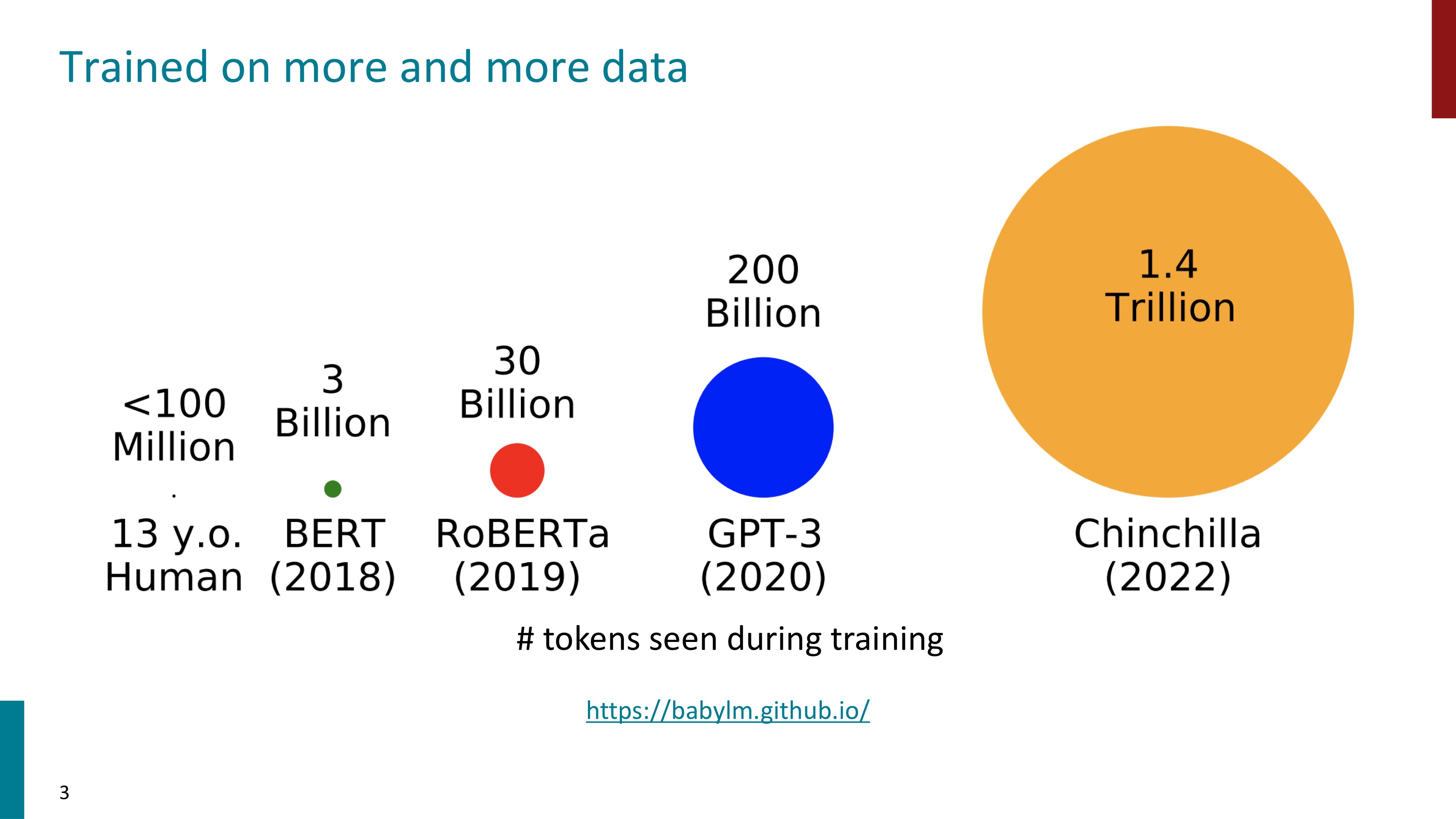





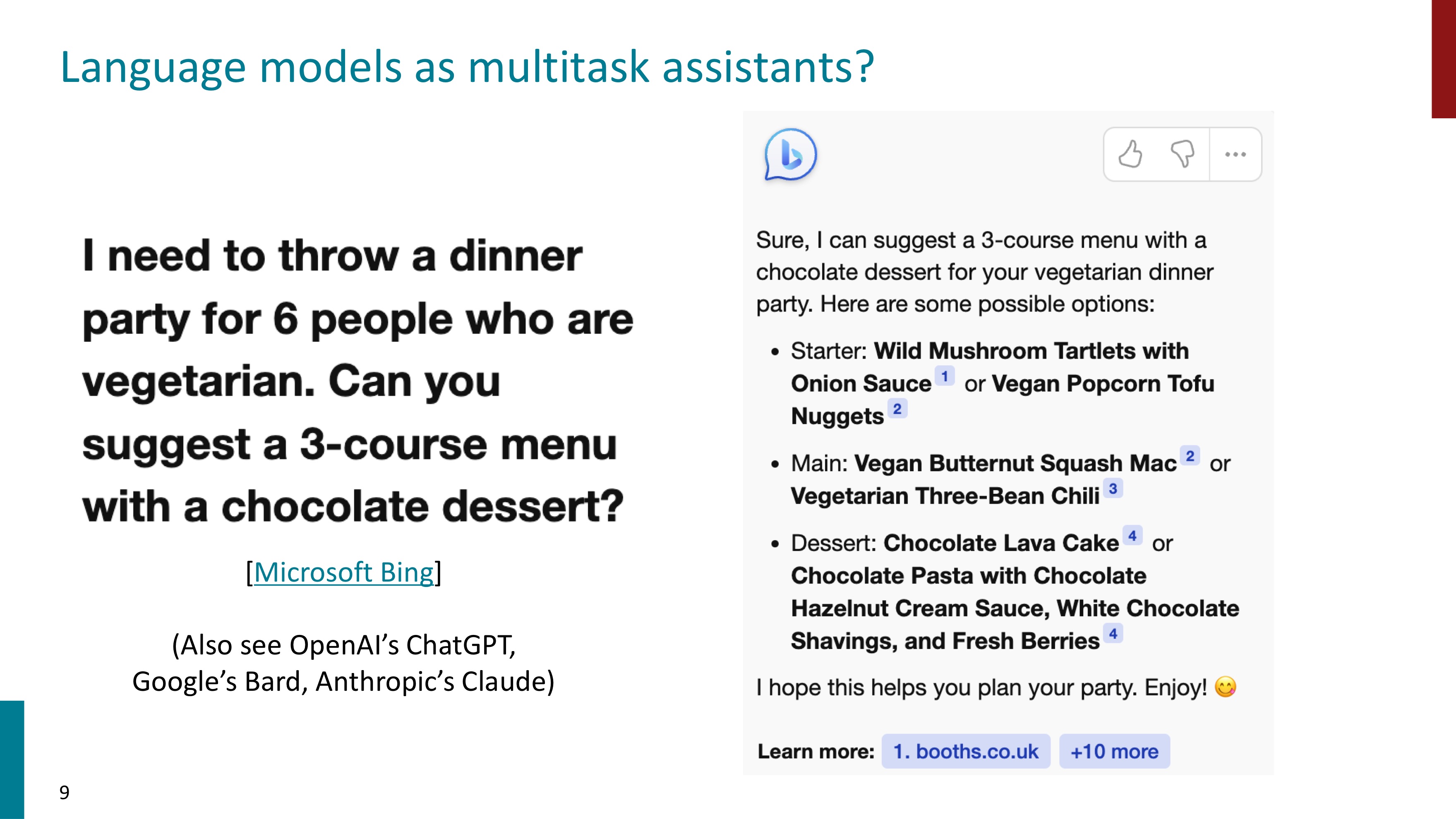
언어 모델의 사이즈와 data는 어마어마하게 커져왔다. 이렇게 Pretrainied된 언어모델로서 기초적인(agents, beliefs, actions) 언어 모델링을 수행할 수 있다.
여기서 우리는 그 이상의 문제들(math, code, medicine 등) 까지 다룰 수 있는 multitask assistants로서 언어모델을 사용하고자 한다.


Prompt란 모델에게 주어지는 입력텍스트이고, Prompting이란 언어 모델이 특정 작업을 수행하도록 유도하는 방법이다. 텍스트 기반의 입력을 제공하여 이를 바탕으로 task를 수행하도록 한다. Prompting 방법으로는 Zero-shot 과 Few-shot 등 여러가지가 있는데, 이에 대해 자세히 알아보자.


Generative Pretrained Transformer인 GPT2는 GPT1과 아키텍처는 동일하지만 모델 사이즈가 커지고 더 많은 data를 학습했다.

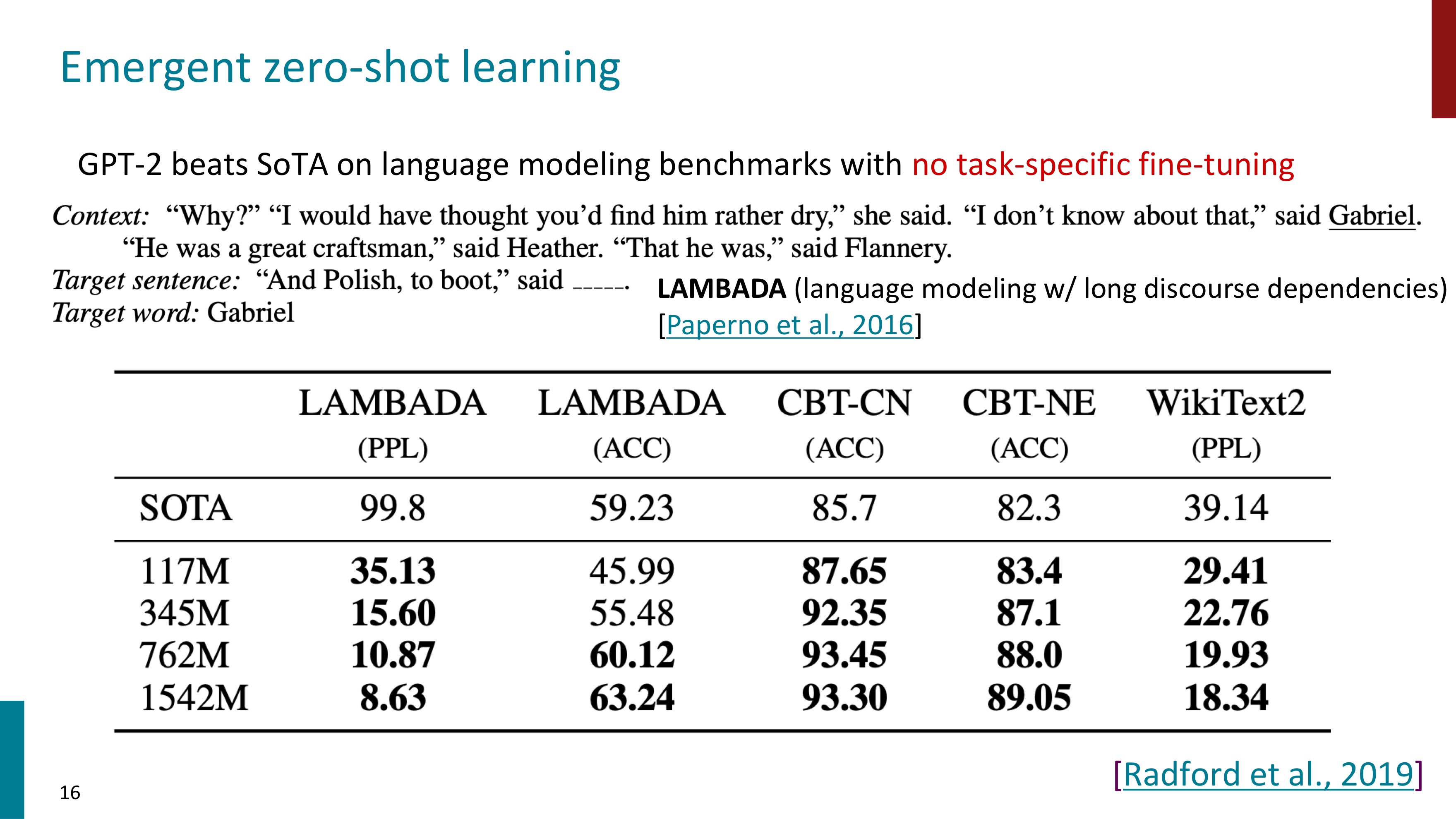
GPT2의 핵심 능력은 zero-shot learning이다. zero-shot learning(ZSL)은 모델이 학습에 사용되지 않은 새로운 클래스나 개념에 대해 예측을 수행하는 방법이다. 즉, 학습에 사용되지 않은 새로운 클래스나 개념에 대한 task가 주어져도 모델은 이를 새로 학습하지 않으므로, gradient update를 하지 않는다. 간단히 말해서 Zero-shot learning은 학습하지 않은 task를 수행하는 것이다.
(gradient update란 모델이 학습 데이터를 통해 점차 더 나은 예측을 하도록 하는 과정을 말한다. 이를 통해 모델은 주어진 데이터의 특성을 학습하고 손실을 줄여나가면서 최적의 파라미터를 찾는다.)
Zero-shot learning은 학습하지 않은 task를 수행하는 것인데, 이게 어떻게 가능할까? ZSL은 이미 다양한 데이터로 Pretraining된 모델을 사용한다. 이 모델은 광범위한 입력 데이터를 일반화할 수 있는 능력을 가지고 있어 이를 새로운 클래스나 task에도 적용할 수 있는 것이다.
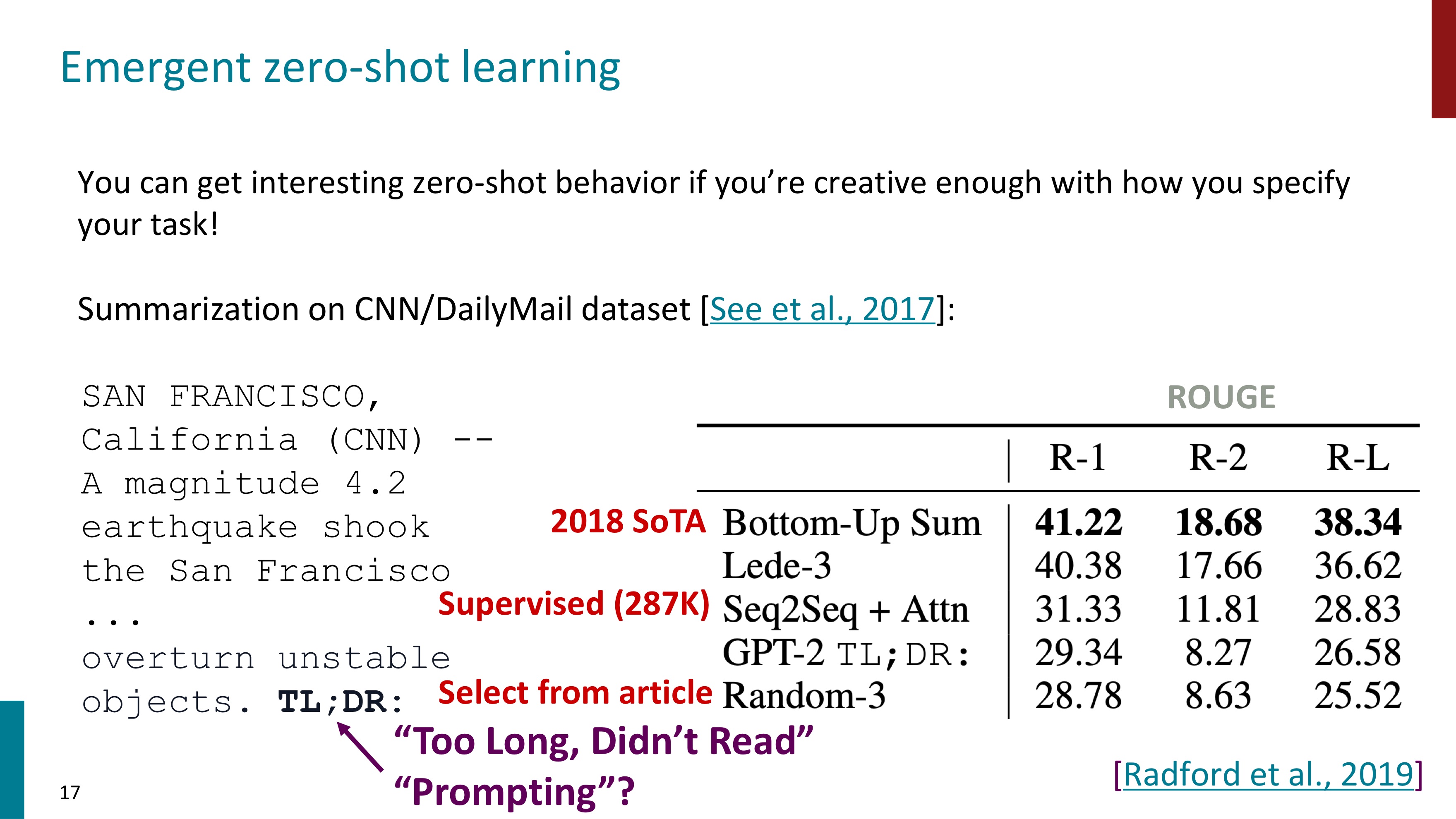
Winograd Schema Challenges task에서는 가능한 시퀀스의 확률을 비교하여 답변을 제공한다. "그것이 너무 커서 고양이가 모자 안으로 들어갈 수 없었다" 라는 문장에서 그것이 무엇인지 묻는 질문에 그것이 고양이일 확률과 모자일 확률을 비교한다. 이 비교 과정에서 cat이나 hat에 대한 추가적인 정보는 없고, 오로지 주어진 문장만으로 확률을 구해서 답변을 제공한다.

GPT3는 few-shot learning과 함께 등장했다. 모델 사이즈가 1.5B에서 175B으로, 또 데이터의 크기도 어마어마하게 커졌다.
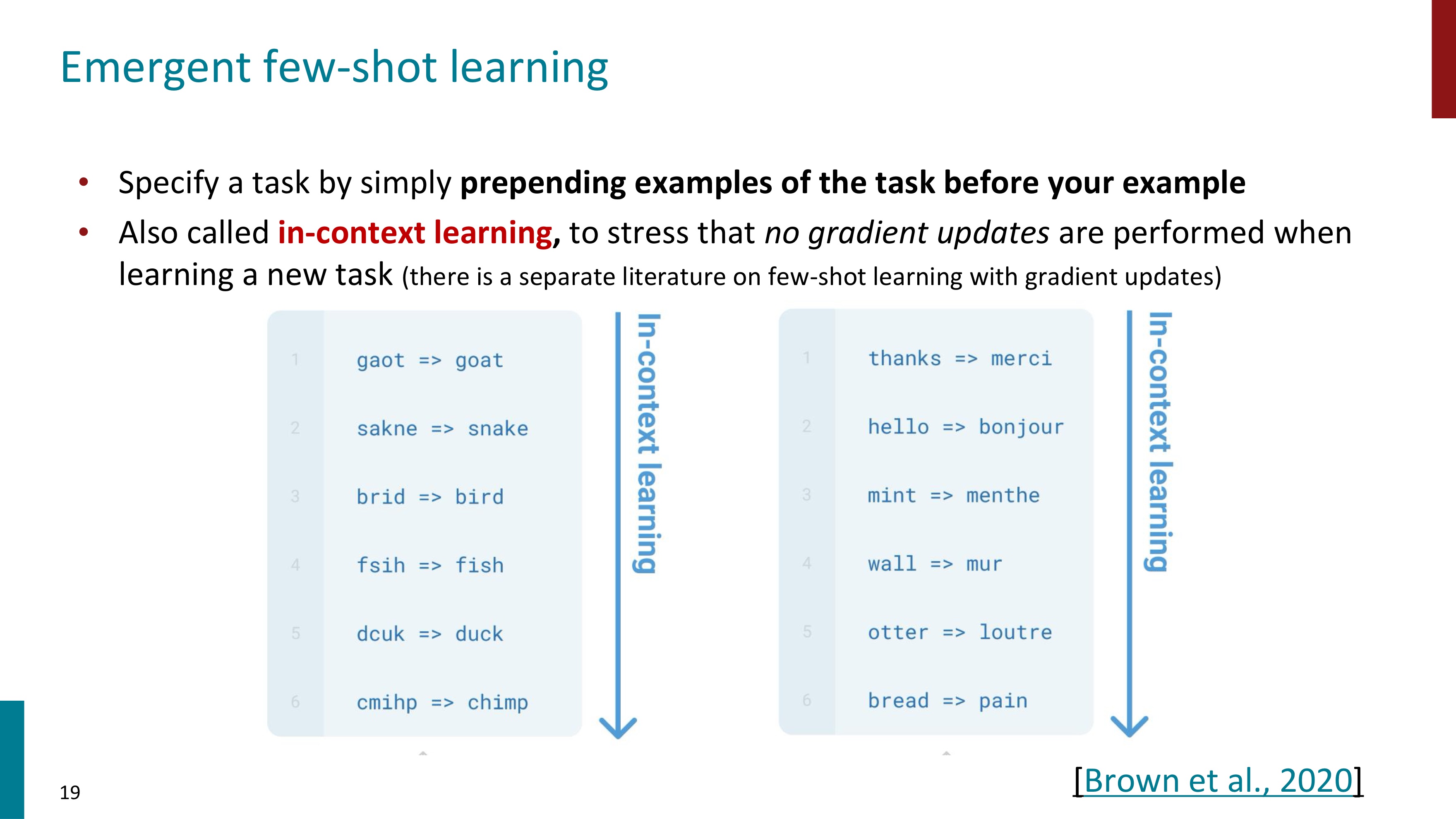
few-shot learning이란 예시를 앞에 추가해서 task를 명확히 하는 것이다. in-context learning이라고 부르기도 한다. Zero-shot learning과 마찬가지로 gradient update는 수행되지 않는다.
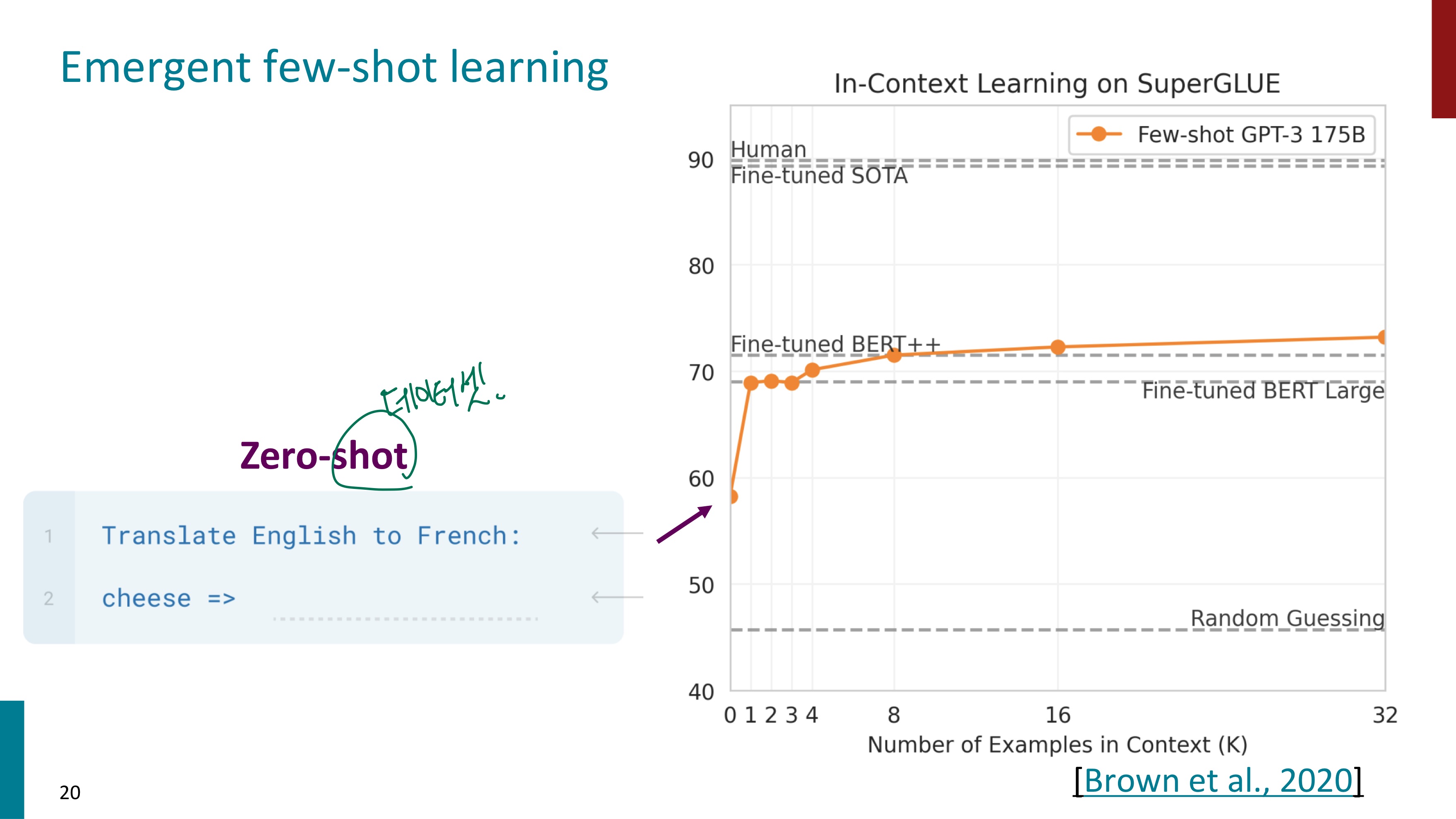
예시를 보자. 먼저 Zero-shot learning이다. 영어를 불어로 translate하라는 task만을 제공한 후 cheese를 넣으니 GPT의 성능은 60 이하이다. 파인튜닝된 BERT Large모델보다도 낮았다.
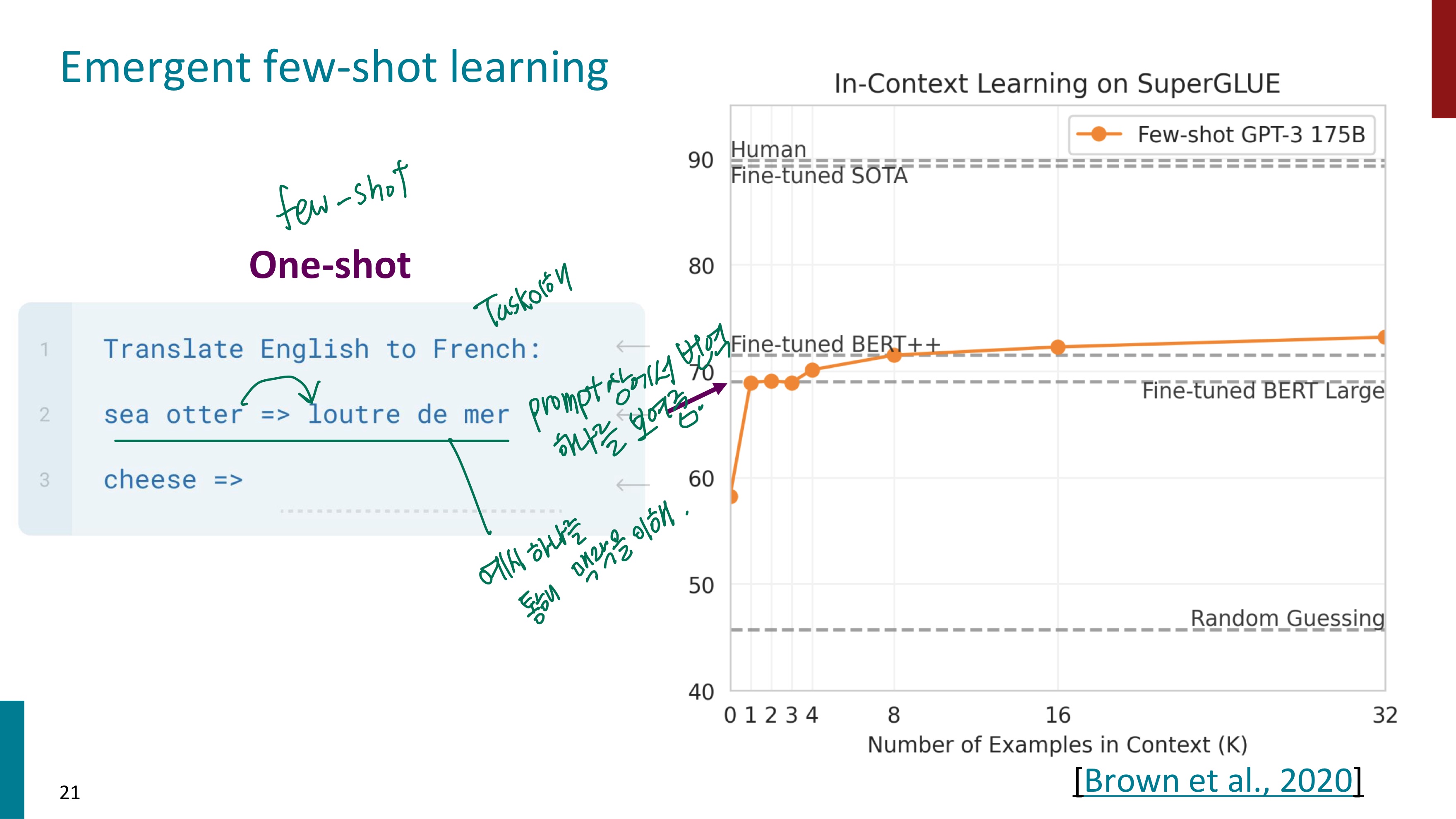
이번에는 task만을 제공한 것이 아닌, 하나의 예시까지 주었다. 모델은 이 예시를 보면서 맥락을 파악하고 task에 대한 이해도를 높인다. task를 제공하기 전에 예시를 하나 제공하는 One-shot learning을 하니 성능은 급격히 상승했다. 하나의 예시를 제공한 것만으로 10 이상성능이 올라간 것을 확인할 수 있다.
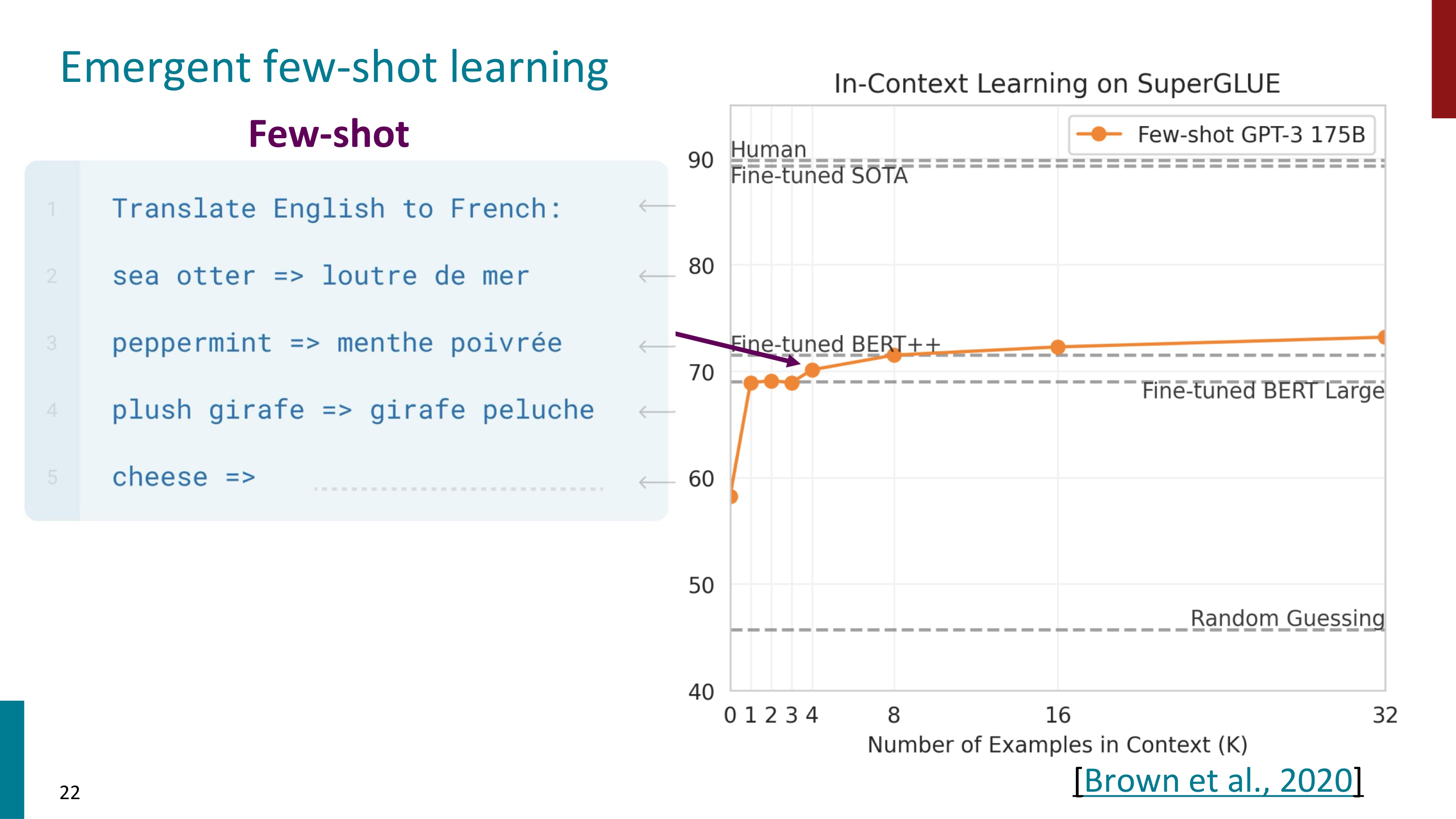
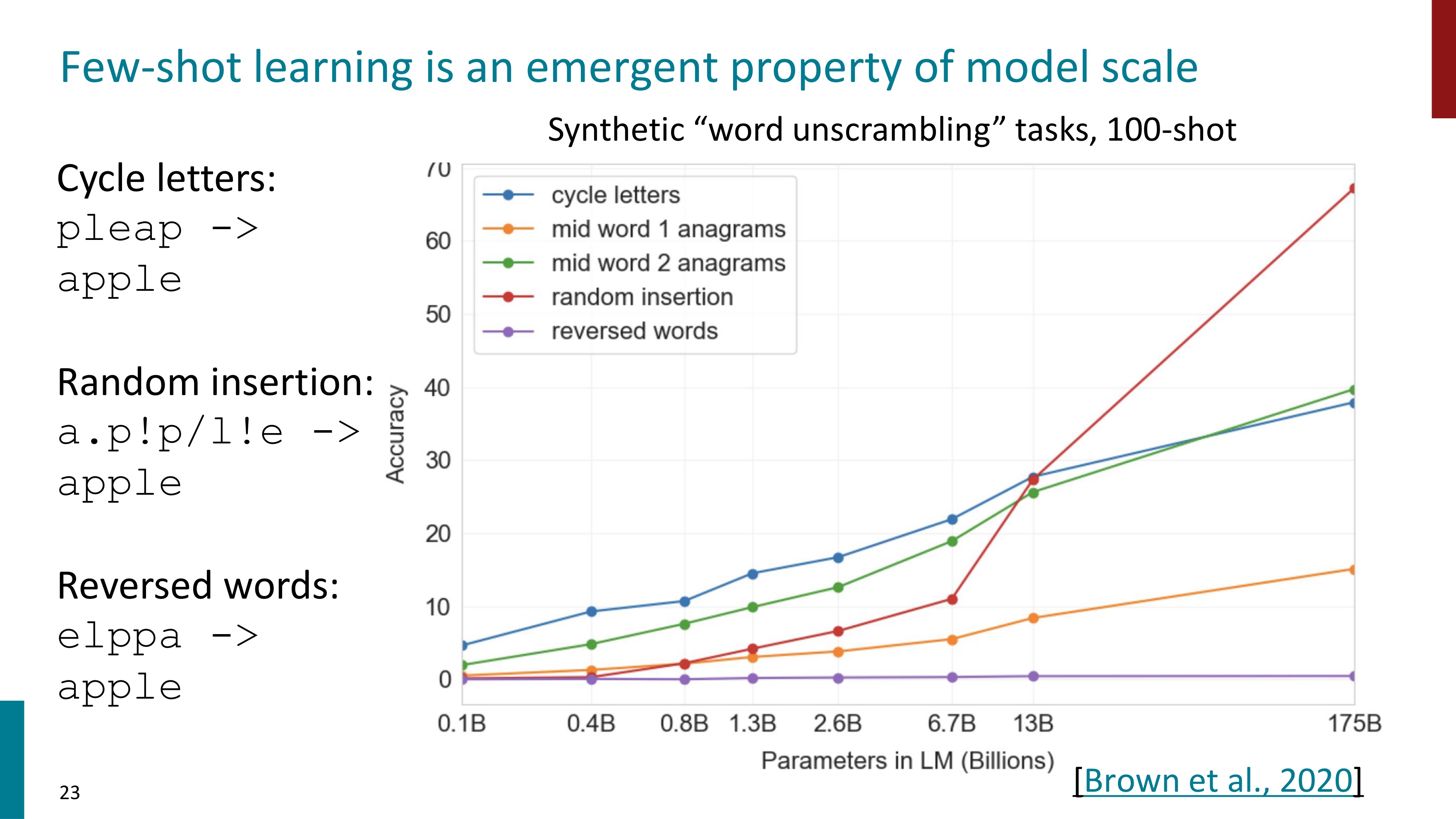
예시 하나를 넣었다고 성능이 매우 증가했는데, 더 많이 넣으면 어떨까?(Few-shot learning) task 전에 3개의 예시를 넣어보았는데, 예상 외로 성능은 크게 달라지지 않았다. 더 많은 예시를 넣자 증가하기는 하지만 기울기가 매우 완만하다.

기존의 전통적인 방식에서는 gradient update의 과정을 거쳐 새로운 클래스들을 학습(fine-tuning)했다. 하지만 Zero/Few-shot Prompting으로 gradient update과정 없이 수행이 가능하다.
gradient update를 하지 않으므로서 모델은 더 유연해진다. Prompting의 장점은 아래와 같다.
(1) 데이터 효율성
별도의 학습이 필요하지 않으므로 데이터가 적거나 새로운 태스크가 등장했을 때도 잘 동작할 수 있다.
(2) 모델 재사용성
파라미터 변경 없이 사전학습된 모델을 그대로 사용한다. 하나의 모델을 다양한 태스크에 유연하게 적용시킬 수 있다.
(3) 유지 보수 및 업그레이드의 용이성
모델의 파라미터를 수정하지 않는 덕분이다. (2)와 같은 맥락이다. 예를 들어 새로운 제품이 출시되었을 때, 그에 대한 정보만 추가적으로 프롬프트에 반영하면 바로 질문 응답 기능을 수행할 수 있다.
(4) 학습 비용 절감
모델을 다시 fine-tuning(재학습)하는데 발생했던 계산 자원과 시간을 절약할 수 있다. 특히 파인튜닝 비용이 큰 LLM에서 이는 더 큰 장점이 된다.
(5) 데이터 오버피팅 방지
fine-tuning은 특정 데이터셋에 모델이 오버피팅될 위험이 있는데, prompting은 사전 학습된 일반적 지식을 활용하기 때문에 오버 피팅 문제를 피할 수 있다.

Prompting으로 더 고난이도의 작업을 맡길 수 있을까? 수학적인 연산을 시킬 수 있을까?
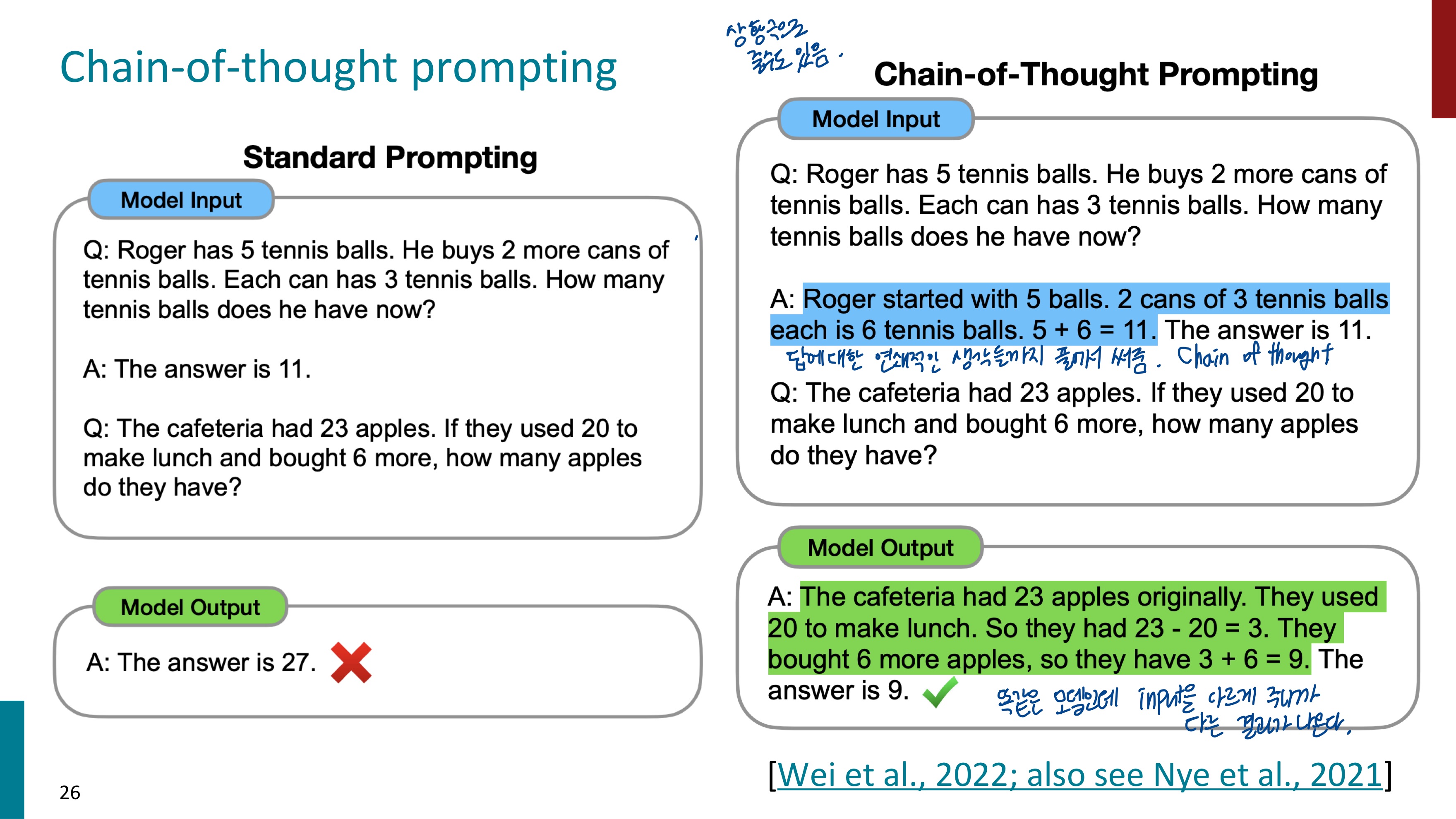
이를 해결해보고자 Chain-of-thought prompting이 등장했다. 이는 모델에게 Prompt로 문제를 푸는 과정의 연쇄적인 생각들까지 함께 제공하는 것이다.
우측의 Standard Prompting에서는 One-shot Learning으로 수학 문제의 QA를 하나 제공하고, 질문을 했다. 예시가 하나 주어졌음에도 틀린 답변을 제공했다. 하지만 좌측에서는 하나의 예시를 제공할 때 Chain-of-thought prompting을 사용했다. 예시의 Answer에서 답변만 제공한 것이 아닌, 풀이 과정까지 알려주었다. 그러자 모델도 똑같이 풀이 과정을 제공하며 답변도 올바르게 제공했다. 같은 모델인데 prompt에 input을 다르게 제공하는 것만으로도 모델의 성능이 높아진 것이다.
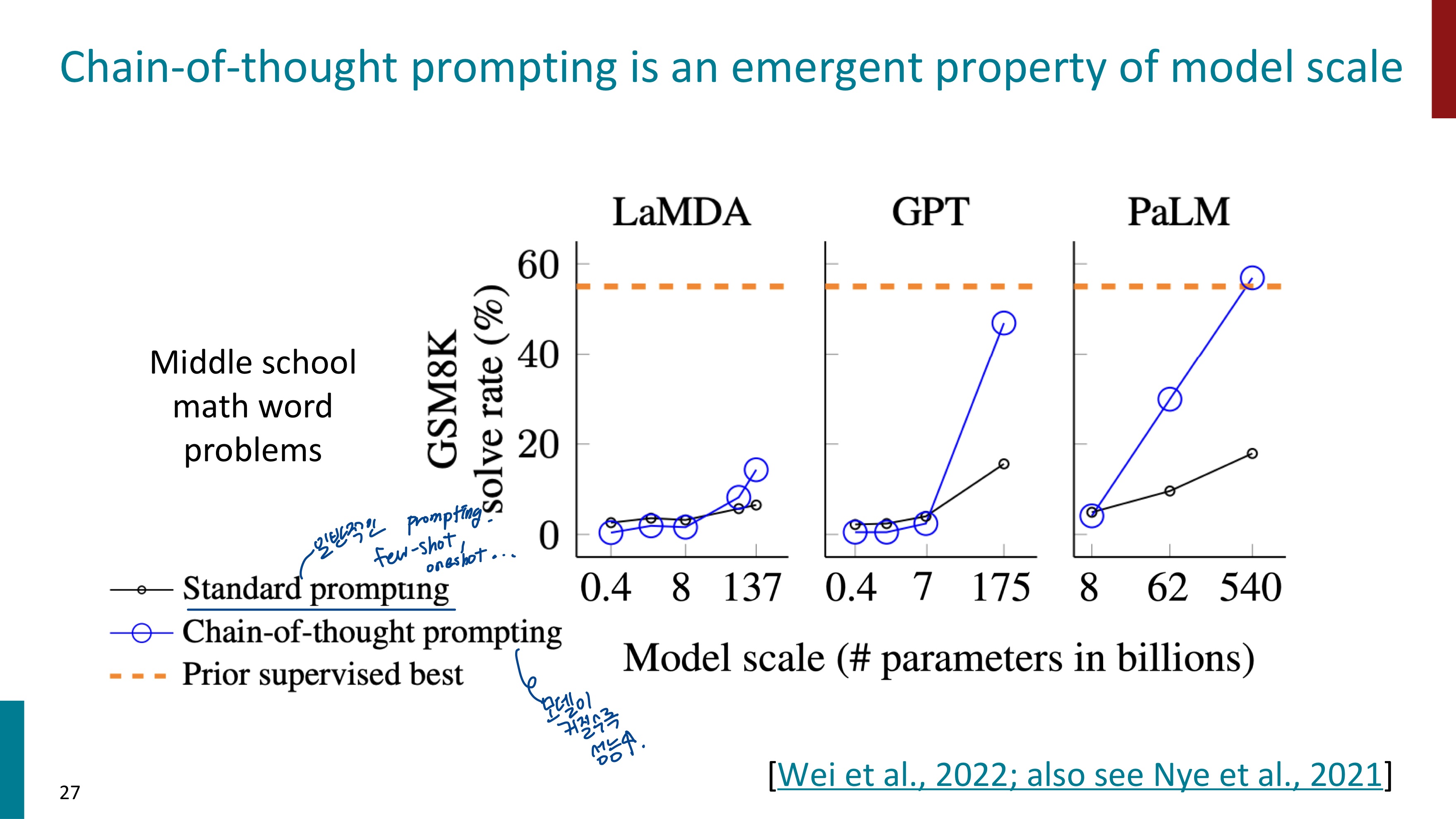


Let's think step by step이라는 문장 하나를 추가한 것만으로도 Chain-of-thought를 수행할 수 있다. 이 문장이 같이 주어지면 알아서 단계별로 문제를 해결한다는 것이다.





더 이상 fine-tuning이 필요하지 않다. Prompting만으로도 성능을 크게 높일 수 있다.
하지만 문맥으로 조정할 수 있는 것에는 한계가 있고, 복잡한 task는 gradient 조정을 필요로 할 것이다.


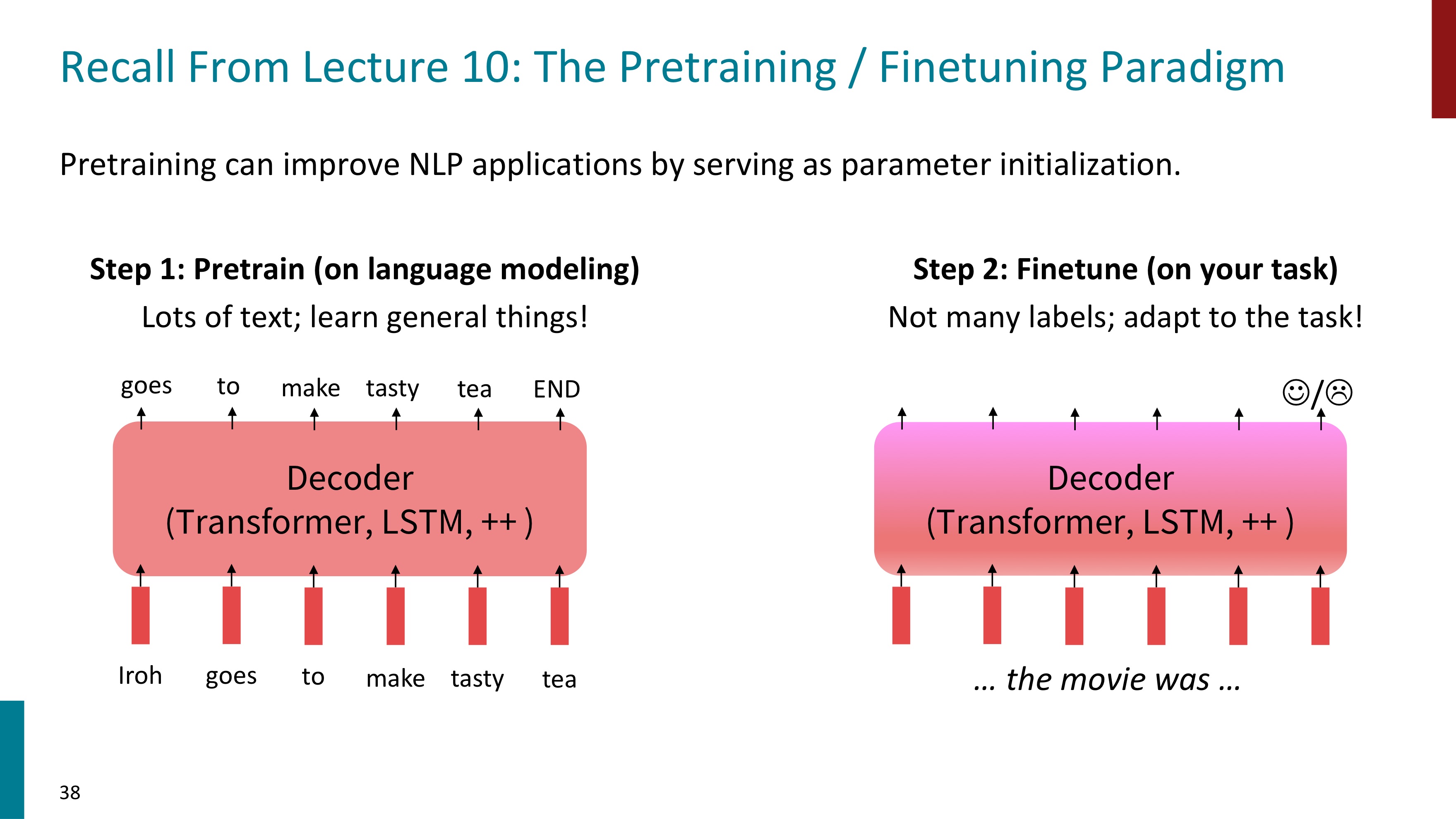
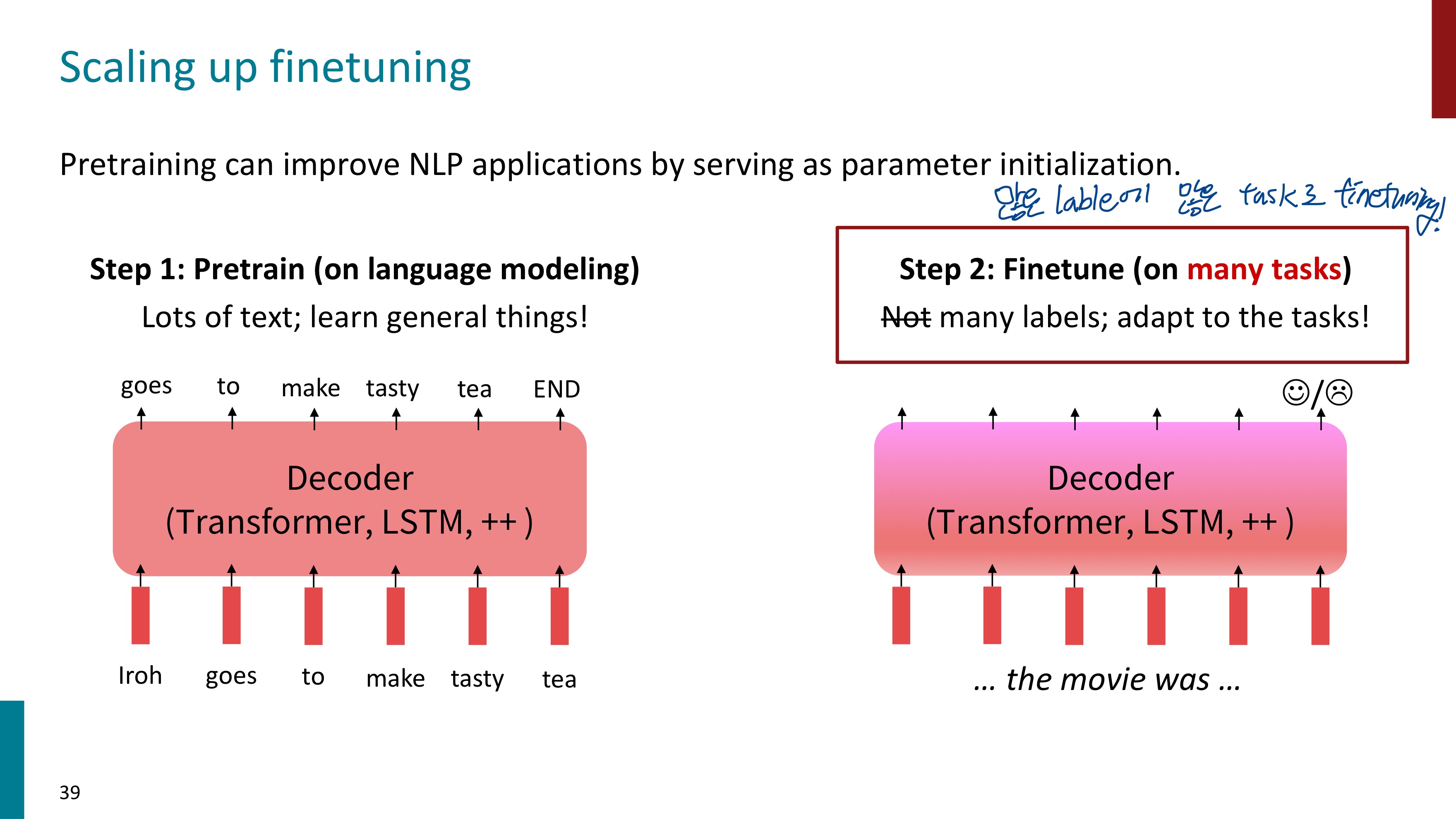
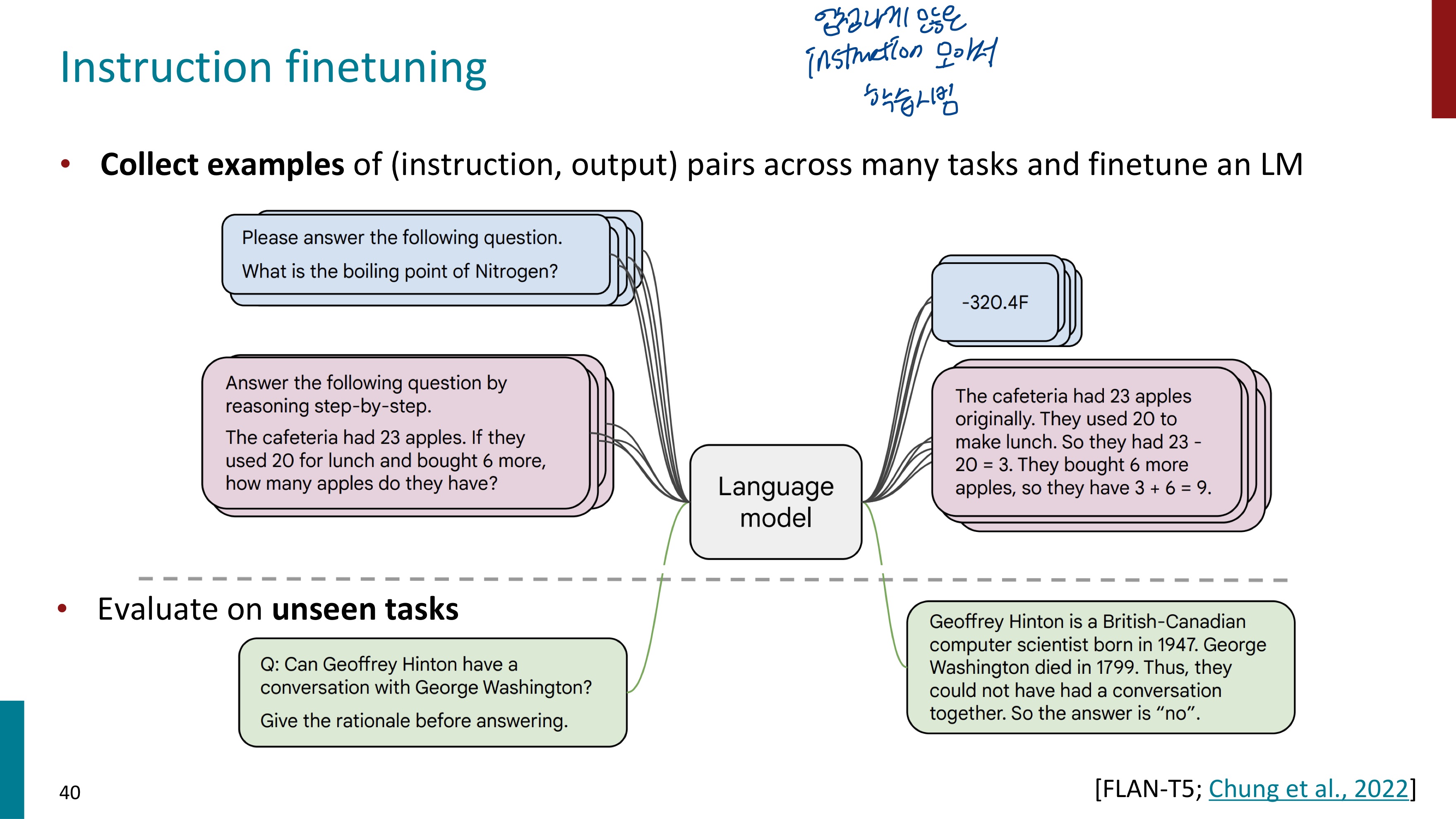
우리는 지금까지 사전학습된 모델으로 적은 수의 lable을 fine-tuning하는 학습 방식을 배웠다. 그런데 이번에는 많은 lable로 fine-tuning을 해볼 것이다. instruction finetuning을 수행할 것이기 때문이다. instruction과 output에 대한 data들을 모아서 LM에 fine-tuning시킨다.
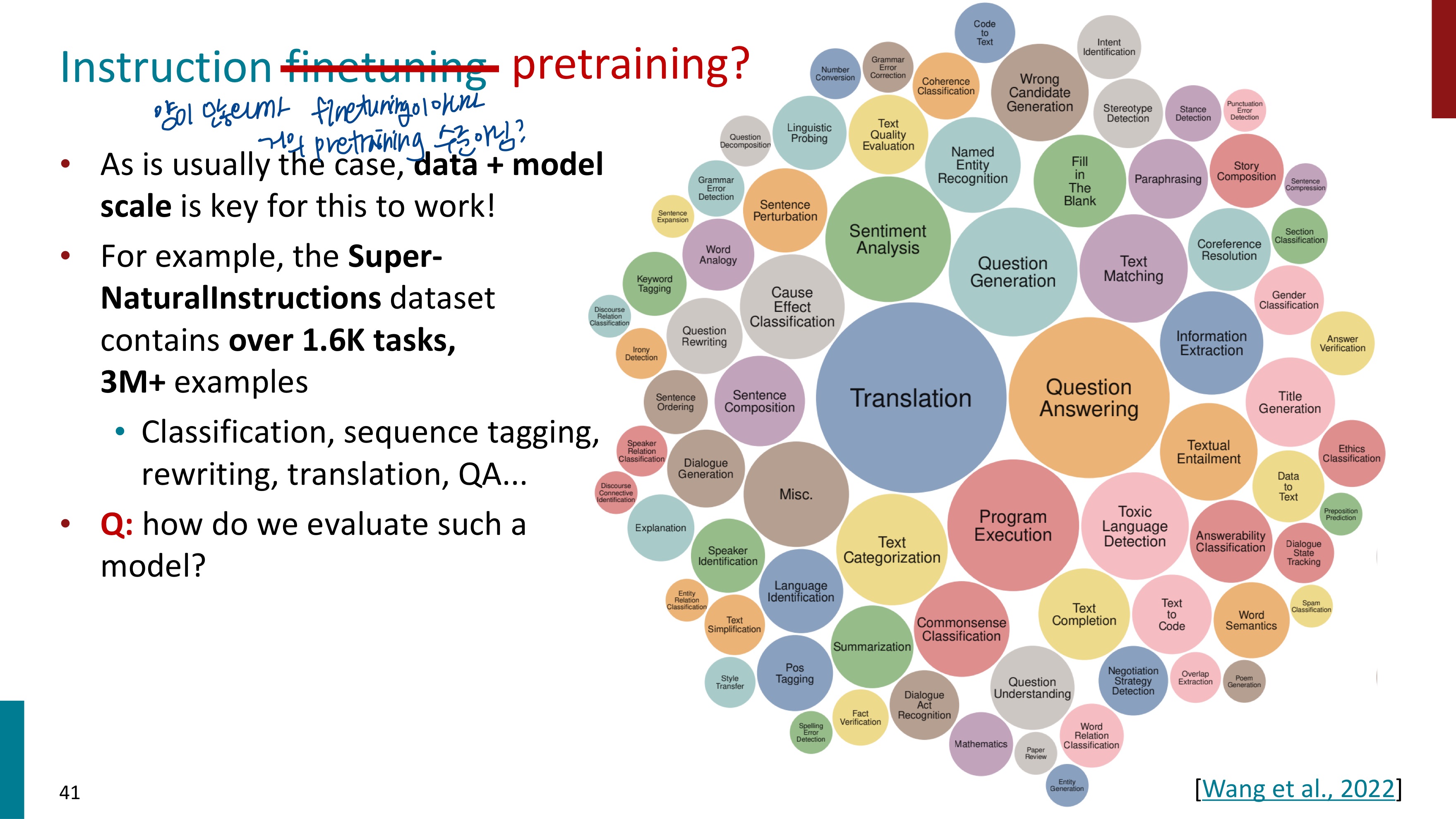
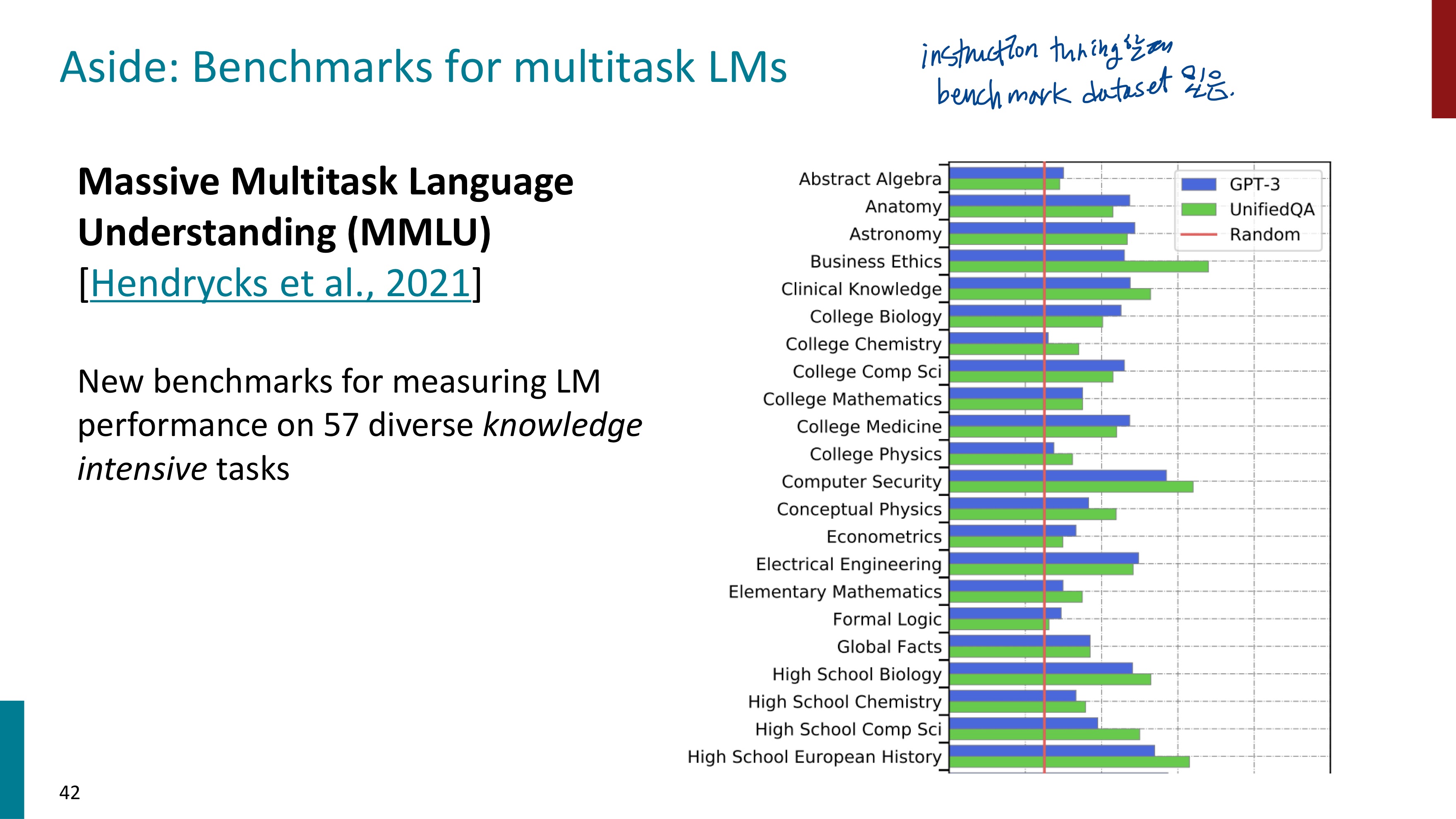
MMLU는 LM을 측정하는데에 사용되는 benchmark dataset인데, instruction finetuning을 평가할 때 사용할 수 있다.




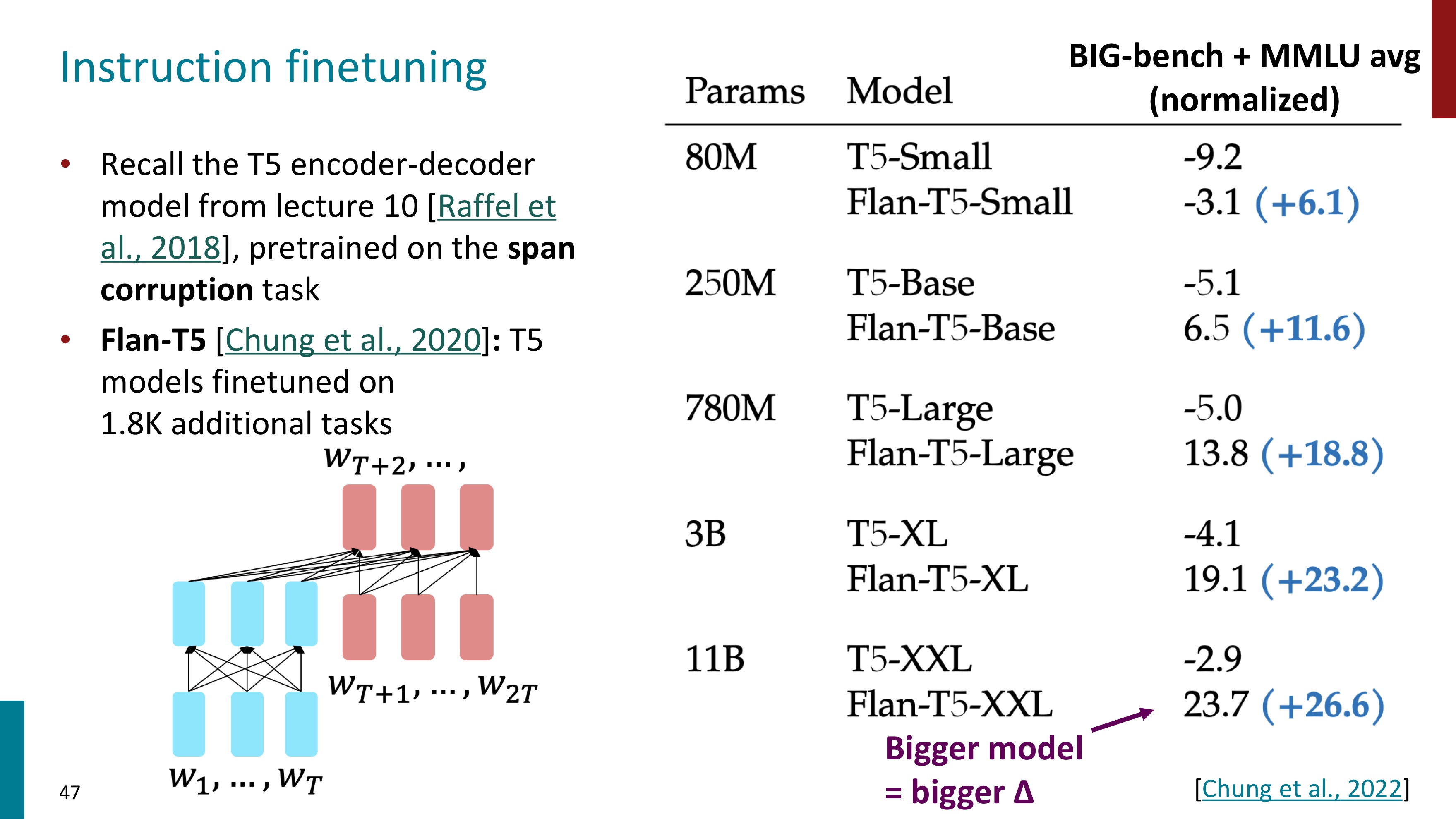
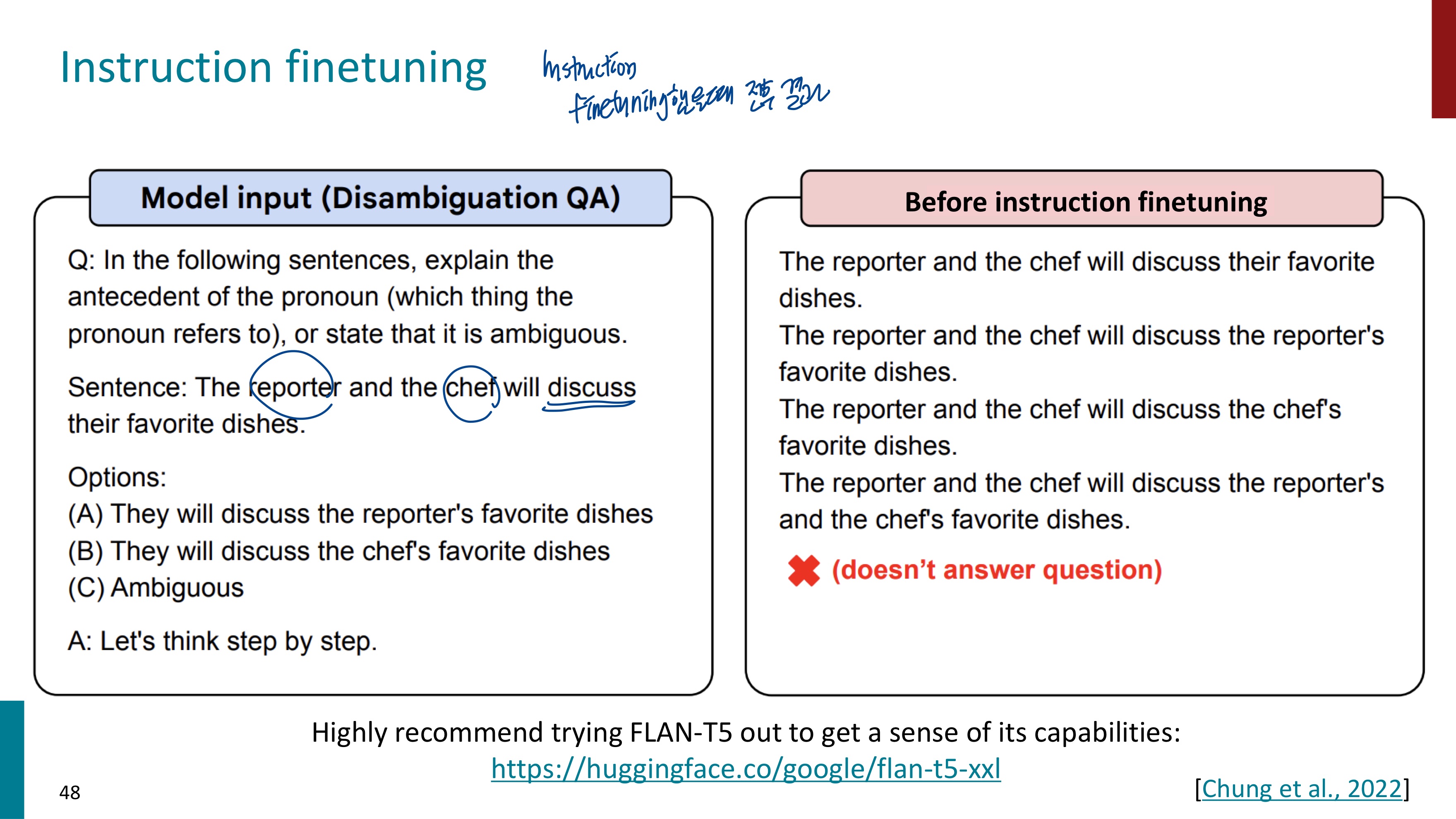
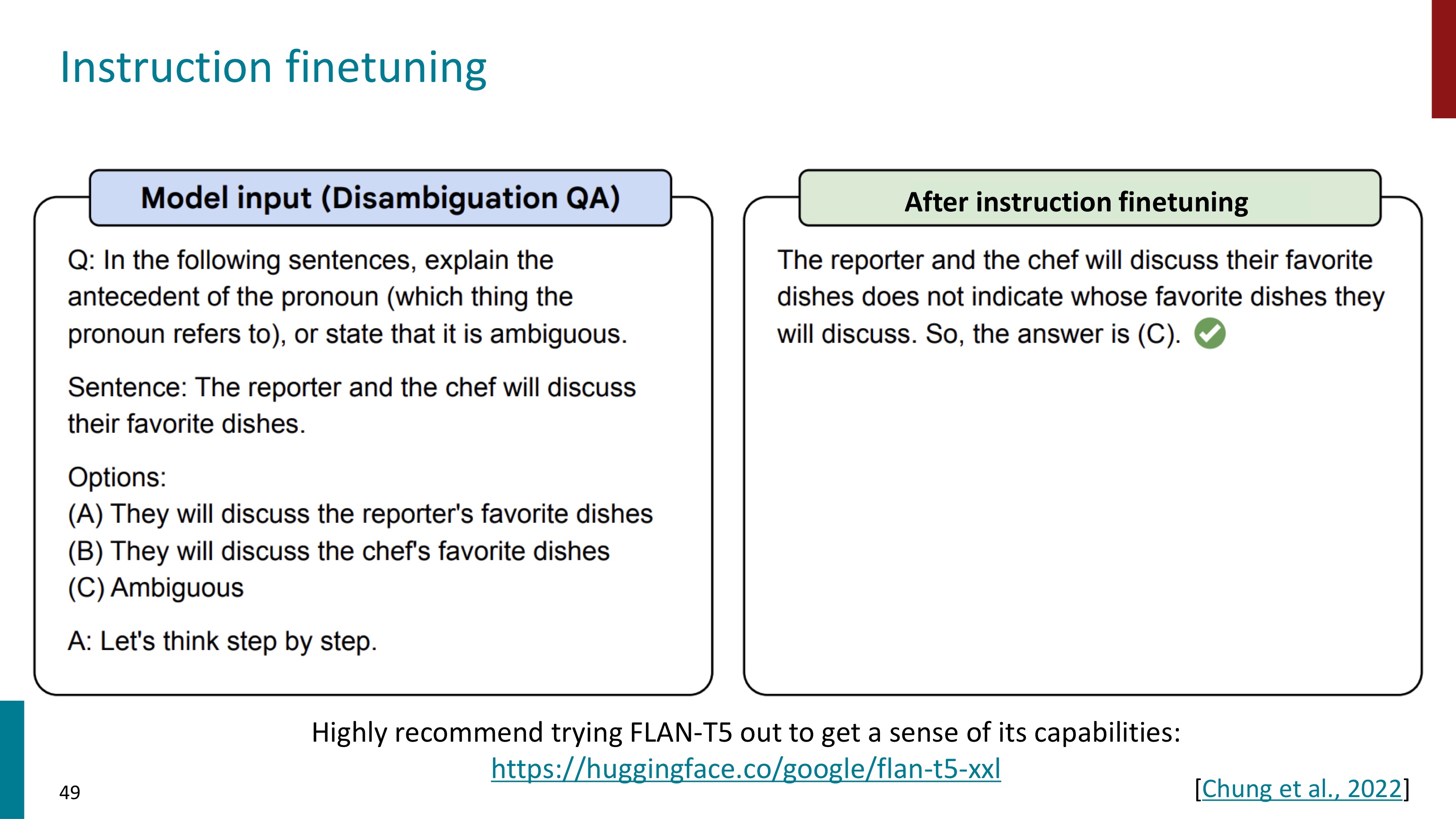

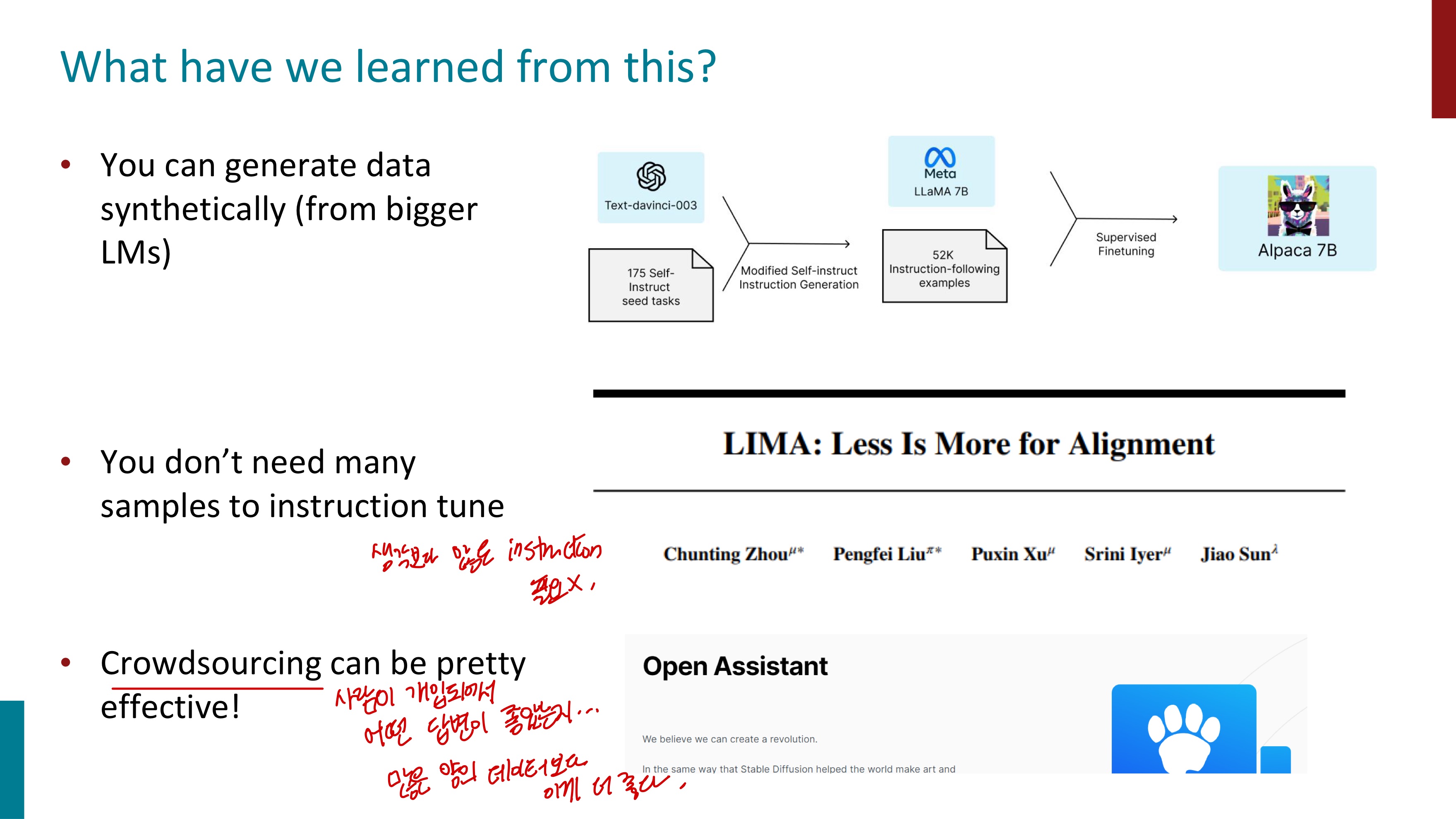
음

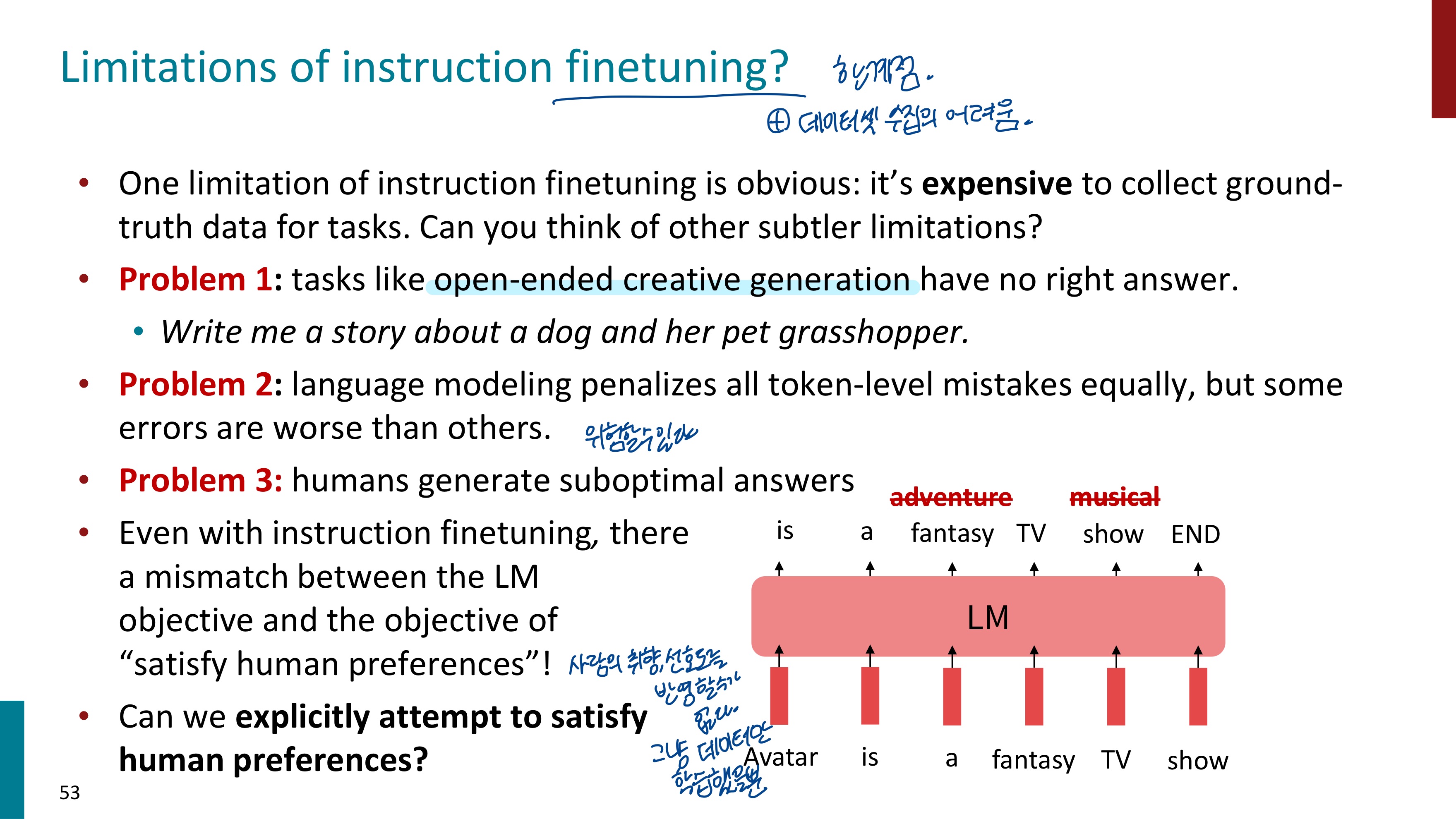
instruction finetuning의 한계점은 데이터 수집이 어렵다는 것이다.
Problem1) 정답이 없는 open-ended task의 경우 잘 수행하지 못한다. 정답이 없는데 학습할 정답 데이터를 제공하기도 애매하다.
Problem2) 언어 모델은 모든 잘못된 토큰에게 똑같은 penalty를 주지만, 어떤 토큰은 더 큰 penalty를 받아야 할 수도 있다.
위 자료를 보면 아바타에 대한 답변을 생성할 때 fantasy가 아니라 adventure라고 했지만, 그렇다고 해서 크게 문제 될 것은 없다. 그런데 show를 musical이라고 하면 이는 문제가 된다. adventure과 musical 모두 틀린 token이지만 penalty가 동일하게 적용되면 안될 것 같다. adventure보다는 musical에 더 큰 penalty가 적용되었으면 좋겠다.
Problem3) 사람은 다른 답변을 생성할 수도 있다. 다양한 사람들에게서 다양한 답변이 나올 것이므로 질문에 대한 답변이 다를 것이다. 언어 모델은 그냥 데이터만 학습한 것이므로 사람의 선호도를 반영하지 못한다.


instruction finetuning은 prompt learning이 가지는 문제점들을 해결할 수 있었다. 간단하고 정확하게 unseen task까지 일반화해서 잘 수행할 수 있었다. 하지만 데이터 수집 비용이 매우 비싸고 사람과 모델의 답변에도 차이가 크게 존재한다. 어떻게 해야 사람의 선호도까지 반영할 수 있을까?

언어모델이 instruction x에 대해서 두 개의 답변 y1과 y2를 생성하면 사람이 개입하여 이 두 개의 답변에 각각 Reward를 부과한다. 그리고 이 Reward 값을 최대화하는 방향으로 모델을 학습시킨다. 그러면 사람의 선호도를 반영하는 언어모델이라고 할 수 있겠다.
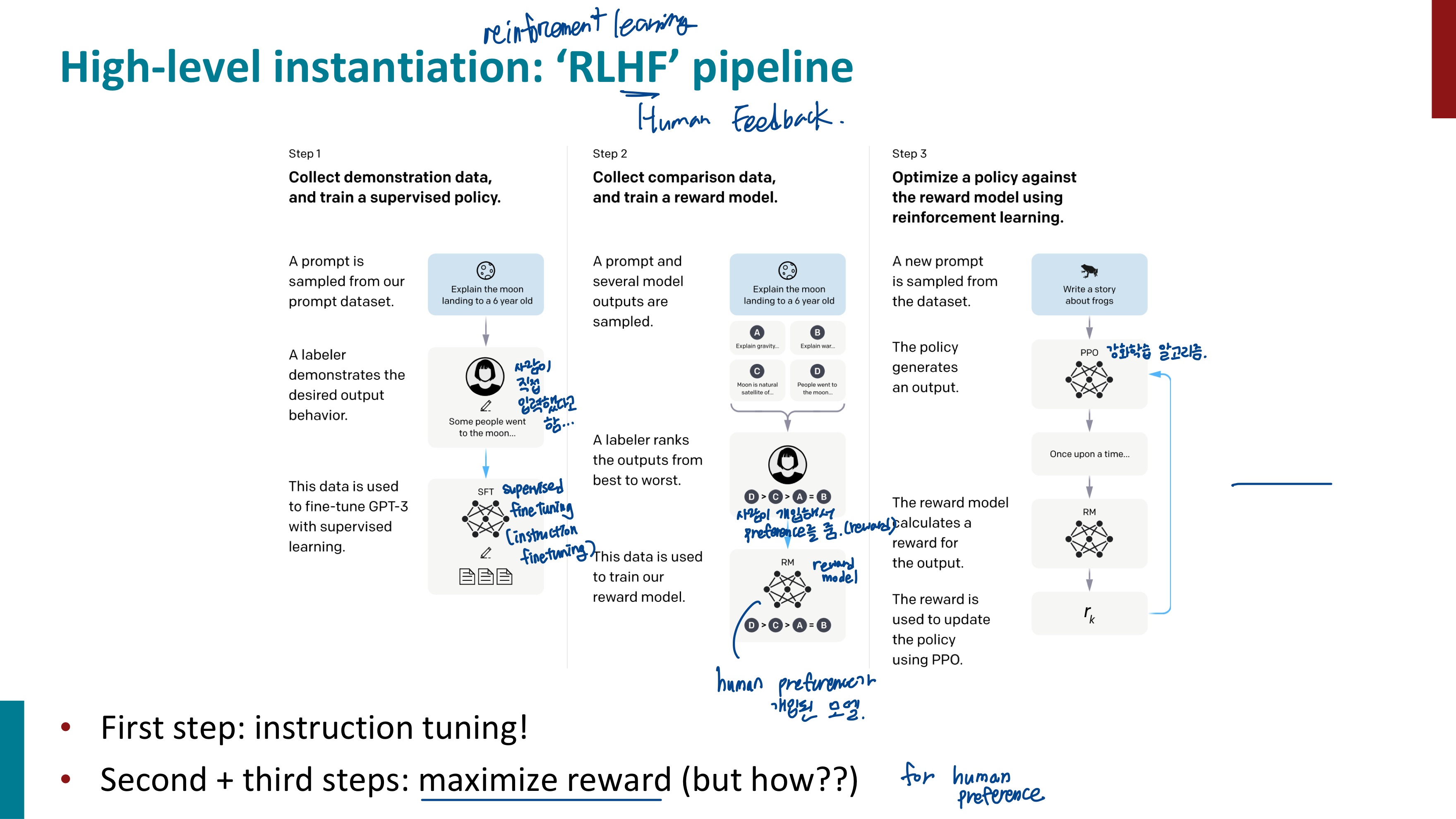
RLHF란 Reinforcement Learning from Human Feedback이다. 사람의 피드백을 통해 모델을 강화 학습하는 것이다. RLHF의 전체 pipeline을 크게 살펴보자.
Step1) 설명 데이터를 수집한 다음, 지도 정책 학습
프롬프트는 데이터에서 샘플링 -> 라벨러가 모범 답안을 설명 -> 이 데이터를 통해 GPT-3 미세 조정
Step2) 비교 데이터를 수집한 다음, 보상 모델을 학습
프롬프트와 여러 모델의 답변이 샘플링 된다 -> 라벨러는 답변들의 순위를 매겨 reward를 준다 -> 이 데이터를 바탕으로 Reward Model을 학습
Step3) 강화학습을 사용해서 RM에 대한 정책을 최적화
데이터셋에서 새로운 프롬프트가 샘플링 된다 -> 정책이 출력을 생성한다 -> RM은 출력에 대한 Reward를 계산한다 -> Reward는 PPO를 통해 정책을 업데이트한다.
이 pipeline을 떠올리며 각각의 단계를 자세히 살펴보자.

Reward를 어떻게 얻을 수 있을까? 사람이 일일이 생성하는 것은 너무 비용이 많이 들기 때문에 Reward Model을 이용한다.
annotated dataset은 x(모델의 입력, 프롬프트)와 y(모델의 출력, 생성된 텍스트) 쌍에 대해 사람이 제공한 reward 정보를 포함한 데이터셋이다. Reward Model은 이 annotated dataset을 이용하여 RM이 x, y의 관계를 통해 Human Reward를 예측하도록 학습한다.
RMϕ(x,y)≈human feedback

사람이 Reward를 매길 때 절대적인 점수를 정하기 애매하다는 문제점도 있다. 이는 절대적인 점수가 아닌, 상대적인 비교를 하는 방식으로 해결할 수 있다.
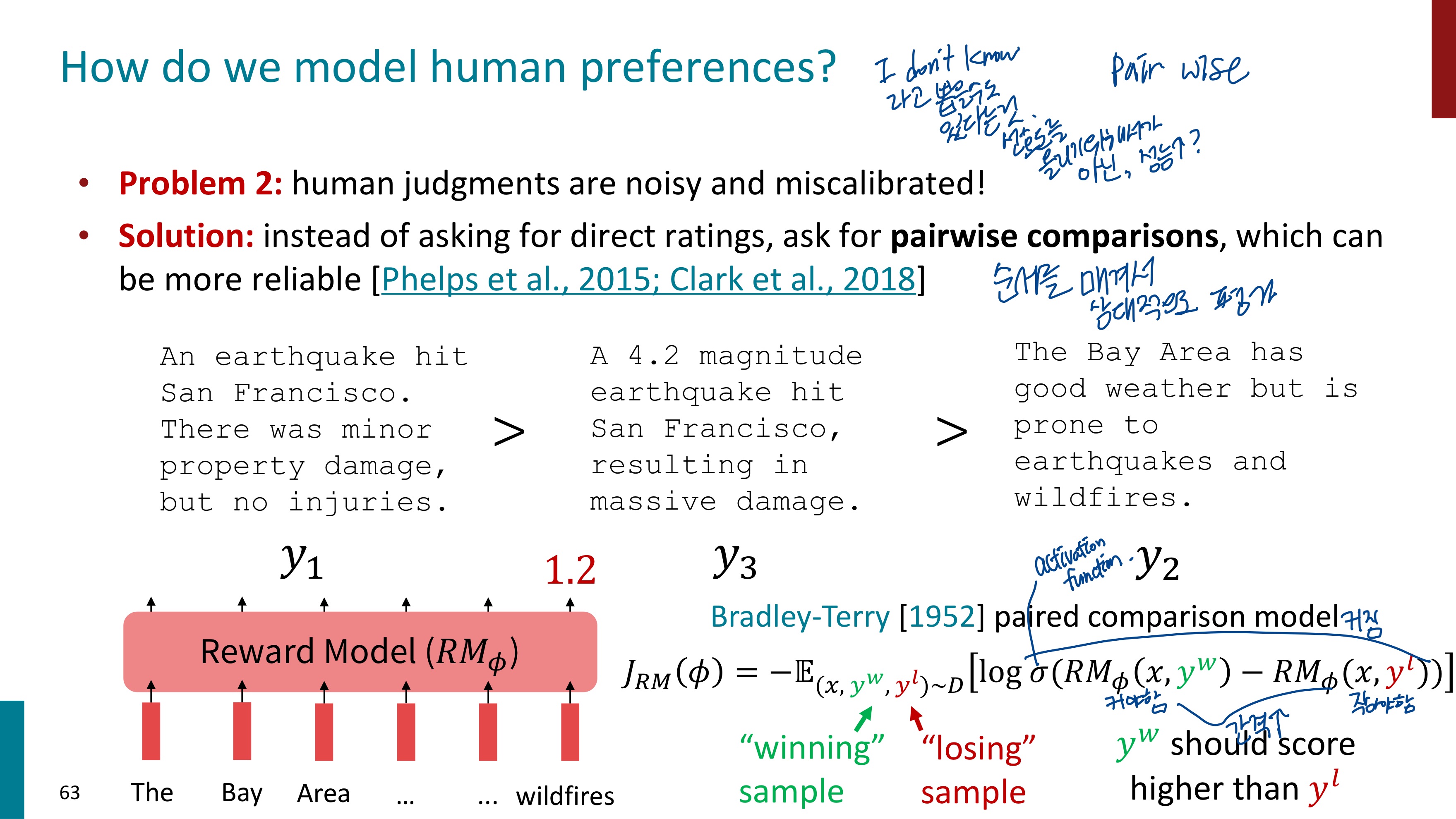
RM 모델이 학습하는 방식을 보여주는 수식이 등장한다. 프롬프트 x가 주어졌을 때 y^w와 y^l이 생성되었는데, 라벨러에 의해 사람의 선호도는 y^w가 더 높다고 reward가 매겨졌다. 그래서 RM은 프롬프트 x가 주어졌을 때 y^w가 출력될 확률을 높이고, y^l이 나올 확률을 더 줄이는 방향으로 학습을 진행한다. 이 방향으로의 학습은 목적함수를 최소화할 것이다.




이렇게 Human Feedback까지 사용하여 성능을 크게 올린 것을 그래프로 확인할 수 있다.
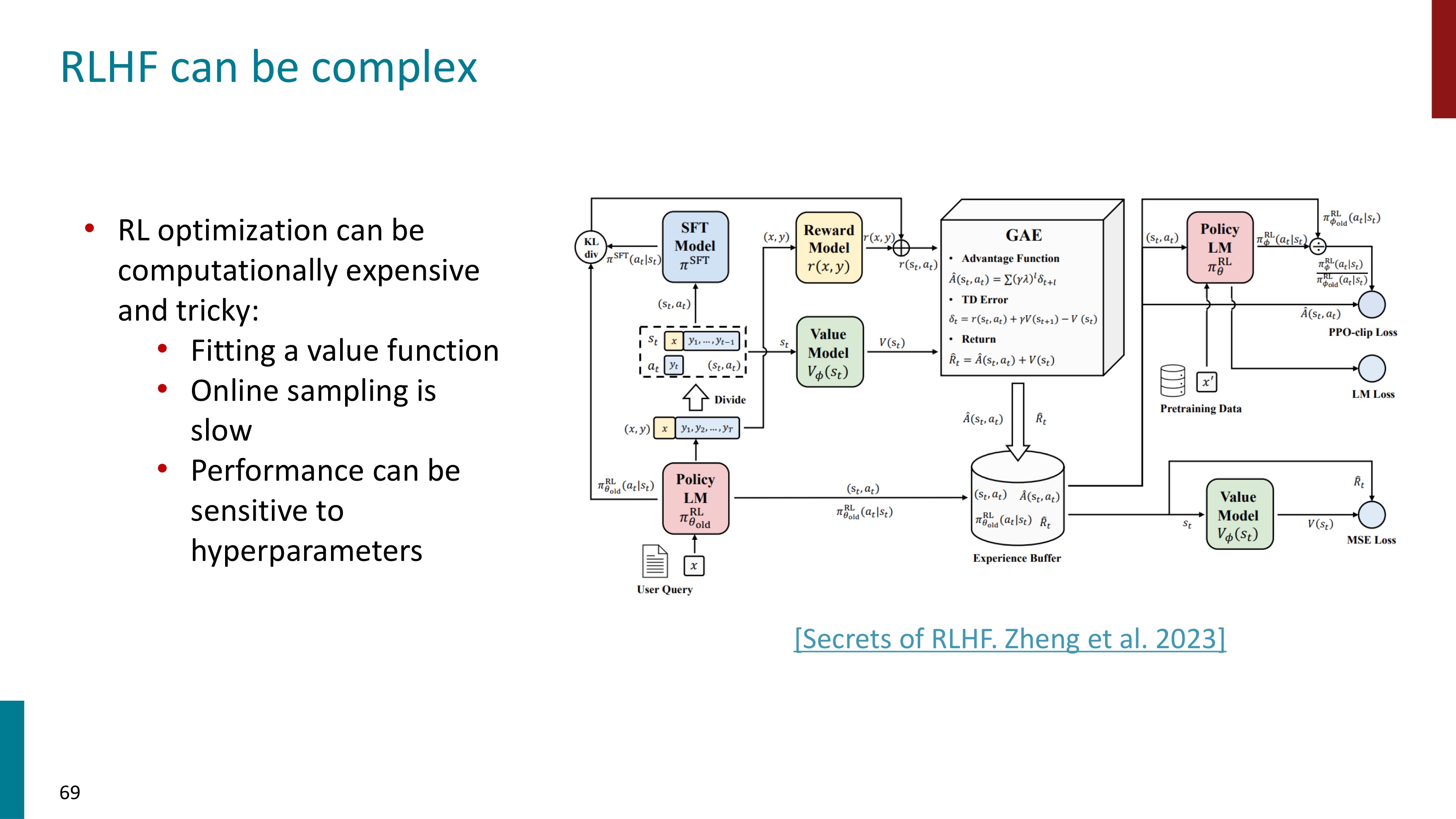

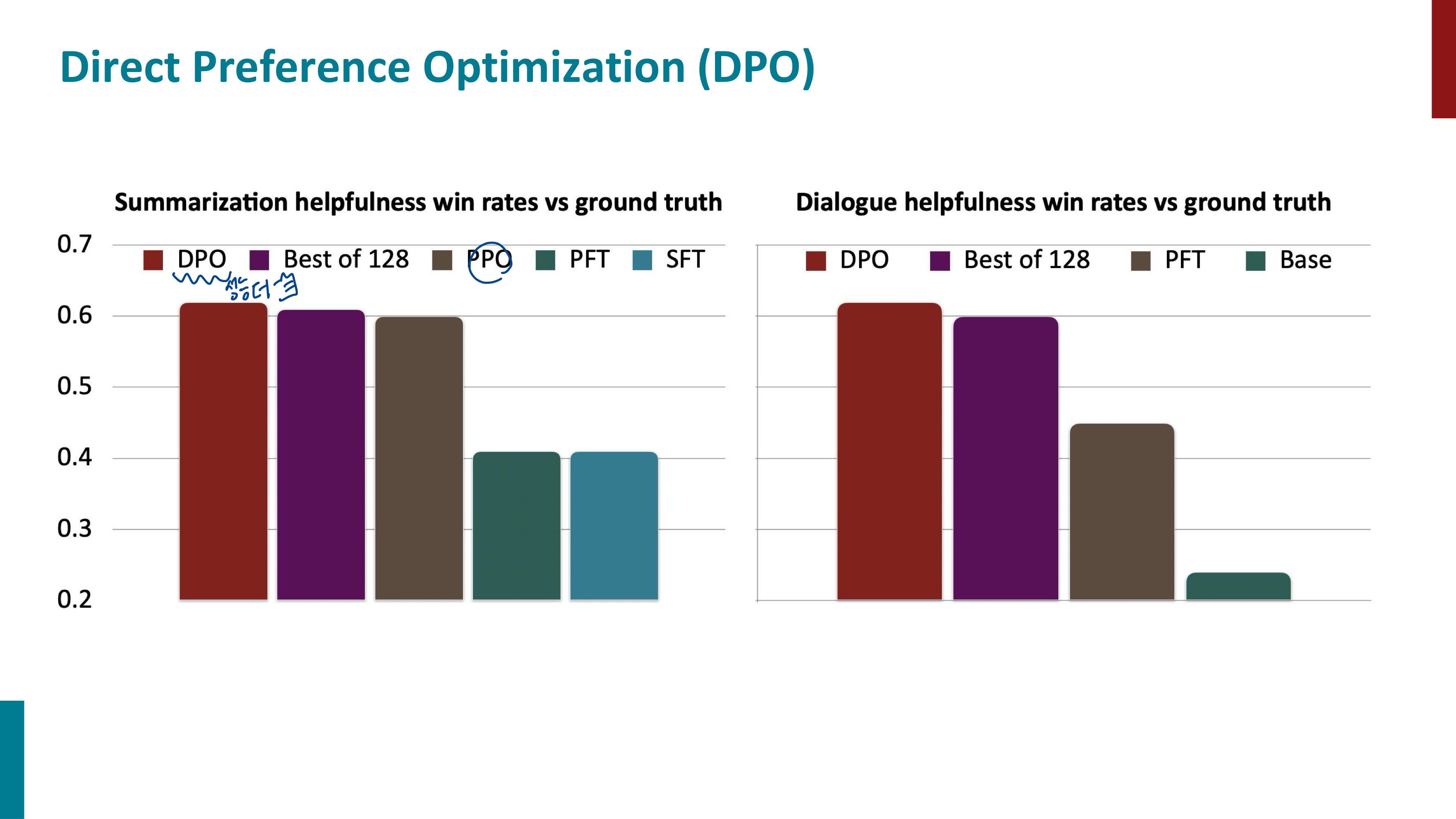
하지만 RLHF는 연산 비용이 많이 들고 어렵다는 단점이 있다. 이는 Direct Preference Optimization, DPO로 해결할 수 있다. DPO는 RLHF의 일부 과정을 단순화하려는 접근법이다. 기본 아이디어는 보상 모델을 직접 최적화하는 대신, 모델의 출력을 선호도 데이터에 맞게 조정하는 것이다.
현재 파이프라인은 보상 모델 RM을 학습하고, 사전학습된 언어모델 LM을 최적화하여 최종적인 RLHF 모델을 생성한다. DPO는 보상 모델을 언어모델의 함수로 표현할 수 있는 방법을 제안한다.



'자연어처리' 카테고리의 다른 글
| [자연어처리] transformer (3) | 2024.06.10 |
|---|---|
| [자연어처리] BERT (1) | 2024.06.09 |
| [CS224N] #9. Pretraining (0) | 2024.05.24 |
| [자연어처리, CS224N] Lec8 : Self-Attention and Transformer (2) | 2024.04.30 |
| [자연어처리, CS224N] #6 - LSTM (1) | 2024.03.29 |