
🌟 Motivating model pretraining from word embeddings
🖇️ Where we were: pretrained word embeddings
우리는 지금까지 사전학습된 워드 임베딩을 사용했다. 하지만 워드 임베딩은 문맥을 고려하지 않는다. 따라서 문맥적 의미는 task를 학습하면서 같이 학습할 수 있는데, 모든 문맥적 의미를 학습할 수 있을만큼의 많은 훈련 데이터를 필요로 하게 된다. 또한 모델의 파라미터들은 랜덤 초기화된다.
🖇️ Where we're going: pretraining whole models
그래서 현대 NLP에서는 전체 모델을 사전학습하는 방식을 사용한다. 이렇게 하면 모델의 파라미터들이 사전학습을 통해 초기화된다. 사전 학습은 입력의 일부분을 가리고, 가려진 부분을 재구성할 수 있도록 모델을 훈련시키는 방식이다. 모델을 사전학습한 방식은 매우 효과적이었다.
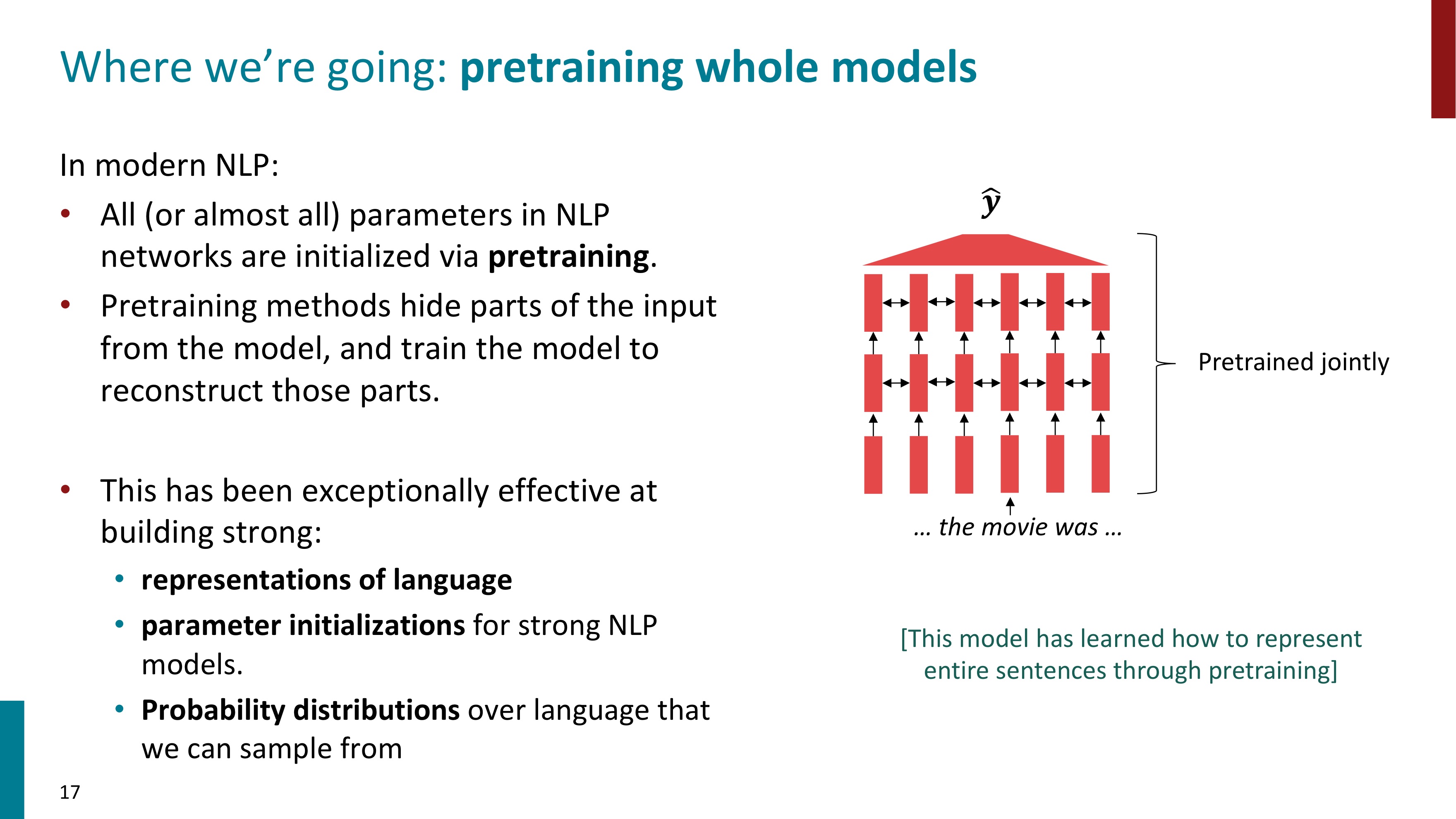
🖇️ Pretraining through language modeling
language modeling task는 t-1개의 단어를 통해 다음, 즉 t번째 단어를 예측하는 task이다. 이 task를 하기 위한 데이터는 매우 많다. 왜냐하면 라벨링이 필요하지 않기 때문이다. 전체 시퀀스가 입력으로 들어가므로 당연히 t번째 단어도 주어지는 셈이다. language modeling을 통해 사전학습을 할 수 있다. 많은 양의 데이터로 학습하고, 네트워크의 파라미터들을 저장한다.

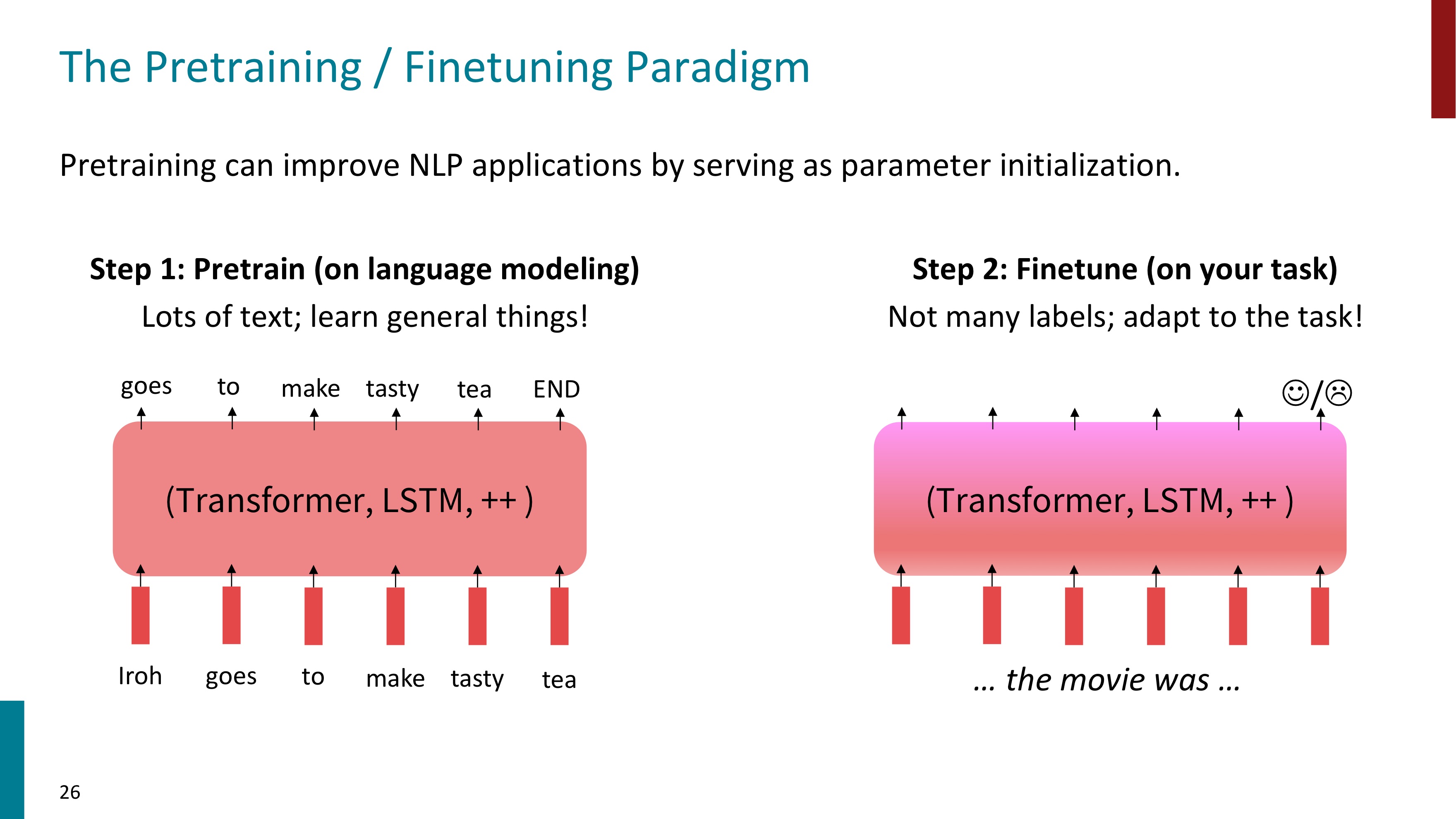
🖇️ The Pretraining / Finetuning Paradigm
사전학습된 파라미터들을 제공하면서 NLP의 성능을 매우 향상시킬 수 있다. 다음 그림과 같은 두 단계로 진행된다. 먼저 대량의 text로 language modeling을 사전학습시킨다. 다음으로는 내가 수행하고자 하는 task에 적합한 data들로 finetuning시킨다. 이미 사전학습을 했으므로 data의 양이 적어도 괜찮다. 아래 그림에서는 감정 분류(긍정/부정)의 downstream task를 위해 finetuning을 했다.
🖇️ Stochastic gradient descent and pretrain/finetune
사전학습을 통한 파라미터로 파인튜닝 과정을 거쳤을 때 더 성능이 좋은 이유에 대한 설명이다. 또한 대부분의 회사들은 충분한 양의 데이터를 가지고 있지 않으므로 사전학습 후 회사에 적합한 task를 위해 finetuning 시키는 방식을 사용한다고 한다. 언어 모델은 사전학습이 거의 필수이다.


🌟 Model pretraining three ways - Encoder, Encoder-Decoders, Decoders
🖇️ Pretraining for three types of architextures
pretraining 방법으로 3가지가 있다.
- Encoders
- 양방향으로 동작한다.
인코더는 입력된 전체 문장을 한 번에 처리하기 때문에 양방향으로 동작한다. 따라서 양방향 정보를 모두 사용할 수 있어 문장의 전후 맥락을 모두 고려할 수 있다는 장점이 있다.
- 양방향으로 동작한다.
- Decoders
- 언어모델(LM)으로 사용된다.
- 생성하는 task에 유리하다.
디코더는 텍스트 생성을 목적으로 설계되었다.
ex) 문장 완성, 텍스트 생성, 번역 등 - 미래를 참조할 수 없다
디코더는 이전 단계까지 생성한 단어들만 사용하고, 아직 생성되지 않은 미래의 단어들은 마스킹하여 참고하지 않는다. 즉 순방향으로만 작동한다.
- Encoder-Decoders
- Encoder와 Decoder의 장점을 결합
입력데이터를 인코딩하고 이를 바탕으로 출력을 생성하는 구조
- Encoder와 Decoder의 장점을 결합
하나씩 자세히 살펴보자. 먼저 Encoder이다.
📍 Encoder
인코더는 양방향으로 문맥을 고려하기 때문에 (bidirectional context) LM으로 사용할 수가 없다.
Idea: 입력 단어의 일부분을 [Mask] 토큰으로 변경하여 예측해보자. (Masked LM)

Bert(Bidirectional Encoder Representations from Transformer)는 Masked LM으로 pretraining된 transformer의 가중치이다. Bert에 대해서는 다음 글에서 자세히 알아볼 것이다.
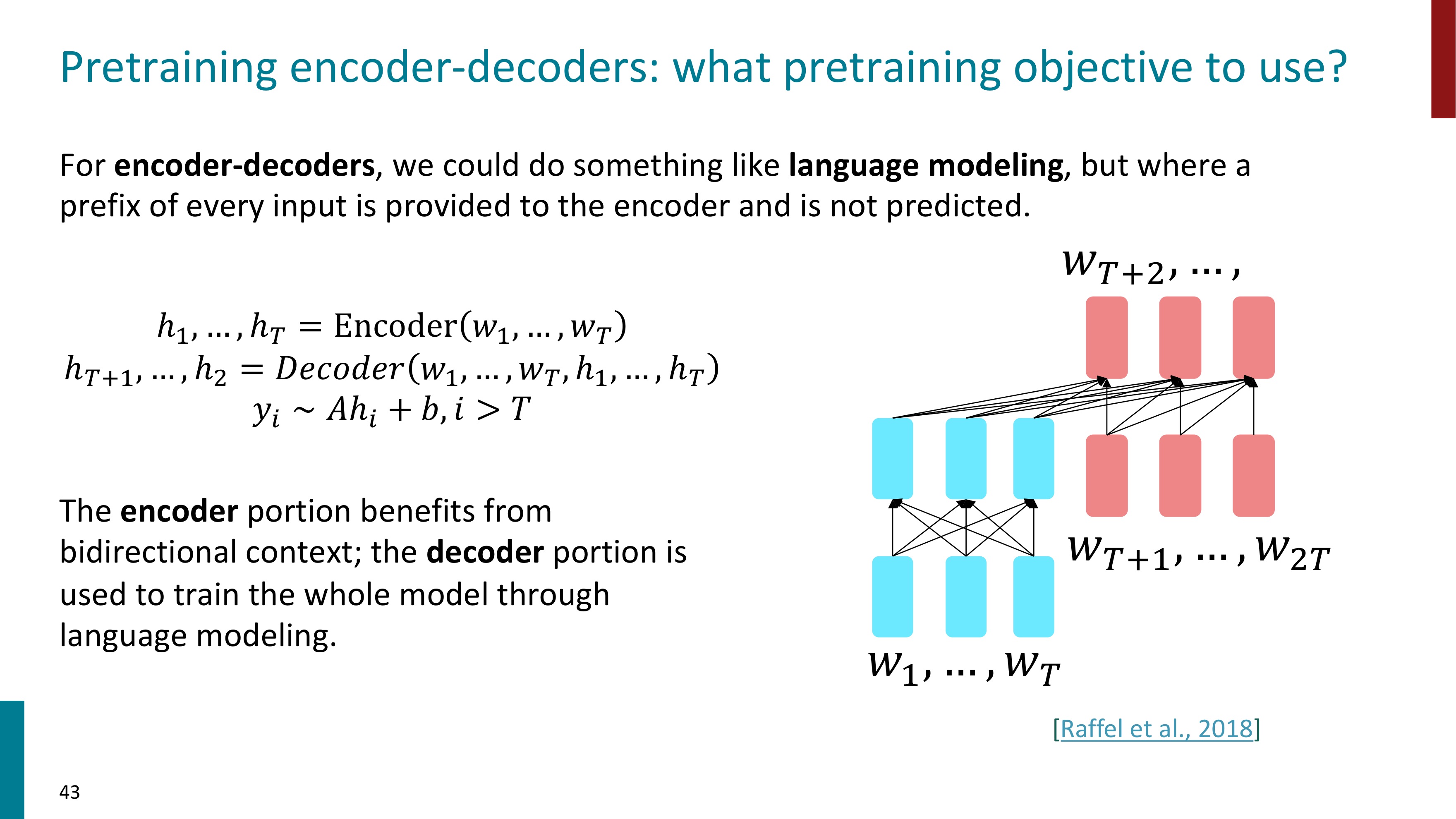
📍 Encoder - Decoders
두 번째로는 Encoder-Decoders 아키텍처를 알아보자.
Encoder-Decoder 모델은 LM처럼 사용할 수 있다. 하지만 모든 input에서의 prefix는 Encoder에 들어가고, 예측되지 않는다.
Encoder로 양방향 문맥을 얻을 수 있고, Decoder는 언어모델링 통해 전체 모델을 훈련하는 데에 사용된다. 이렇게 Encoder와 Decoder의 장점이 결합된다.
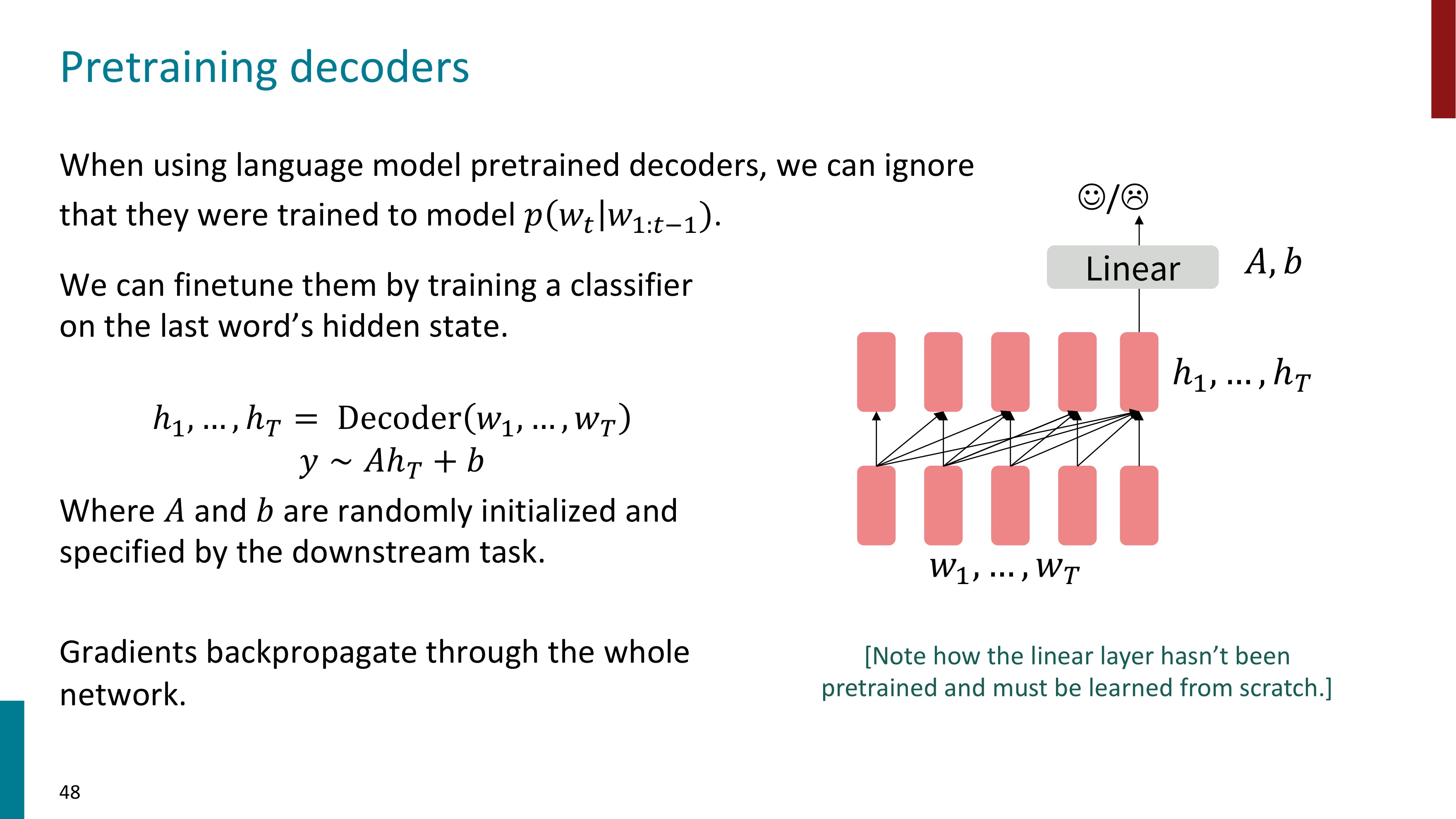
📍 Decoders
마지막으로 Decoder이다. decoders로 사전학습된 언어모델을 사용할 때, 우리는 모델이 다음 토큰을 예측하도록 학습되었던 것을 무시한다. GPT는 decoder로 사전 학습된 모델이다. GPT에 대해서는 다다음 글에서 자세히 알아보도록 하자.
'자연어처리' 카테고리의 다른 글
| [자연어처리] BERT (1) | 2024.06.09 |
|---|---|
| [CS224N, 자연어처리] #10. Prompting (1) | 2024.06.08 |
| [자연어처리, CS224N] Lec8 : Self-Attention and Transformer (2) | 2024.04.30 |
| [자연어처리, CS224N] #6 - LSTM (1) | 2024.03.29 |
| [자연어처리 CS224N] #5-2 Neural Language Model, Perplexity (0) | 2024.03.26 |