Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., ... & Lample, G. (2023). Llama: Open and efficient foundation language models.
arXiv preprint arXiv:2302.13971 (9302회 인용)
https://arxiv.org/abs/2302.13971
LLaMA: Open and Efficient Foundation Language Models
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, witho
arxiv.org
📍 Abstract
LLaMA는 7B에서 65B 매개변수에 이르는 foundation LM의 모음이다. trillions of tokens으로 모델을 학습하였고 public 데이터셋만을 이용하여 SOTA 성능을 낼 수 있는 모델을 학습시킬 수 있음을 보였다. 일부 기업만이 가지고 있는 독점적이고 방대한 비공개 데이터셋을 활용하지 않고도 SOTA 성능을 낼 수 있다는 것이다. 특히 LLaMA-13B는 대부분의 벤치마크에서 GPT-3(175B)보다 성능이 뛰어나고, LLaMA-65B는 최고의 모델인 Chinchilla-70B, PaLM-540B에 견준다. 모든 모델은 오픈소스로 공개된다.
📍 Instruction
그동안 더 많은 매개변수가 더 나은 성능으로 이어질 것이라는 가정하에 모델의 크기를 키우는 방향으로 연구가 진행되었다. 그러나 주어진 컴퓨팅 예산 안에서 최고의 성능은 가장 큰 모델이 아니라 더 많은 데이터로 학습된 더 작은 모델이라는 것을 보인다. 또한 모델이 클수록 inferece 속도가 느려진다. 모델을 실제로 서빙할 때 더 선호하는 모델은 학습 속도가 빠른 것이 아닌 추론 속도가 빠른 모델이다. 그래서 큰 모델을 학습하는 것보다 더 오래 학습하였지만 추론 속도가 빠른 모델이 선호된다.
📍 Approach
[pretraining]
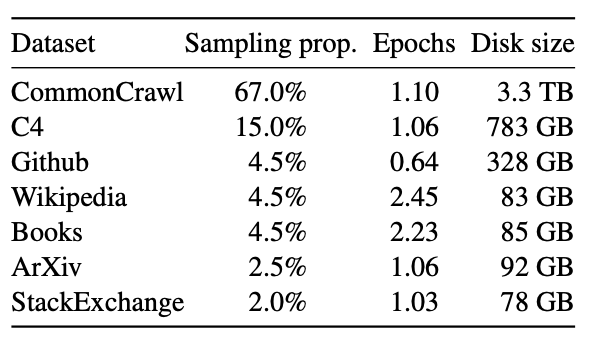
Pre-training에는 다양한 도메인을 포괄하여 여러 소스가 혼합되었다. 모두 공개적으로 사용가능한 데이터이다. 위의 표에 각 데이터셋에 대한 샘플링 비율, 1.4T 토큰에서 학습할 때 하위 집합에서 수행된 에포크 수, 디스크의 크기가 있다. 1T 토큰에서 pretraining을 진행하면 같은 샘플링 비율을 가진다.
BPE(Byte pair Encoding) 알고리즘을 이용하여 데이터를 토큰화했다. 전체 학습 데이터셋을 토큰화하면 1.4T token 정도이다.
[Architecture]
- pre-normalization : 학습 안정성을 개선하기 위해 transformer의 layer 안의 normalization 위치를 바꾼다. 출력을 정규화하는 대신 입력을 정규화한다. LayerNorm이 아닌 RMSNorm을 활용한다.
- SwiGLU activation function : 활성화 함수로 ReLU 대신 SwiGLU를 사용한다.
- Rotary Embeddings : 절대 위치 임베딩을 제거하고 회전 위치 임베딩(RoPE)를 추가한다.
[Optimizer]
AdamW optimizer를 사용하여 학습되었다.
[Efficient implementation]
모델의 학습 속도를 개선하기 위해 여러 최적화가 진행되었다.
1) Casual Multihead Attention 최적화
xformers 라이브러리를 이용해 casual multi-head attention이 사용되었다. 이는 attention 가중치를 저장하지 않고 언어 모델링의 특성상 계산할 필요가 없는(masking을 하기 때문에) Key, Query 스코어를 계산하지 않도록 최적화한 것이다. 이렇게 함으로써 메모리 사용량을 줄이고 속도가 향상된다.
2) 체크포인팅으로 역전화 최적화
체크포인팅이란, 학습할 때 필요한 값들을 일부 저장해서 불필요한 계산을 줄이는 방법이다. 이를 통해 역전파 과정에서 복잡한 계산을 다시 하지 않도록 하여 메모리 사용량과 계산량을 줄였다.
3) 모델 및 시퀀스 병렬화
큰 모델을 학습시킬 때 모델을 여러 GPU에 나눠서 처리하는 모델 병렬화를 사용했다. 또한 입력 데이터를 나눠서 여러 GPU가 동시에 처리하는 시퀀스 병렬화도 사용하여 메모리를 분산시키고 속도를 높였다.
📍 Main results
zero-shot과 few-shot task에 대해 평가가 진행되었다.
- Common Sense Reasoning

- Closed-book Question Answering


- Reading Comprehension
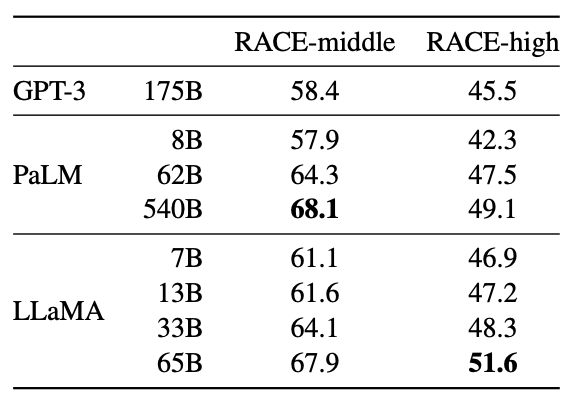
- Mathematical reasoning

- Code generation

- Massive Multitask Language Understanding

- Evolution of performance during training

'엣지컴퓨팅' 카테고리의 다른 글
| Llama3 한국어 요약 task 실습 (Colab) (12) | 2024.11.08 |
|---|---|
| LLaMA2의 GQA 코드 살펴보기 (1) | 2024.10.30 |
| [논문읽기] GQA: Training Generalized Multi-Query Transformer Models fromMulti-Head Checkpoints (0) | 2024.10.07 |
| [논문 읽기] Gemma: Open Models Based on GeminiResearch and Technology (4) | 2024.09.25 |
| [MIT 6.5940] EfficientML.ai Lec03: Pruning and Sparsity (1) | 2024.09.18 |