MIT 6.5940 송한 교수님의 강의를 참고하며 pruning과 sparsity에 대해 정리해보고자 한다. 강의 영상은 아래와 같다. 이해하기 어려운 부분이 많아서 모든 슬라이드를 확실히 짚기보다는 중요한 슬라이드만 부분적으로 정리할 것이다.
https://www.youtube.com/watch?v=95JFZPoHbgQ&list=PL80kAHvQbh-pT4lCkDT53zT8DKmhE0idB&index=6
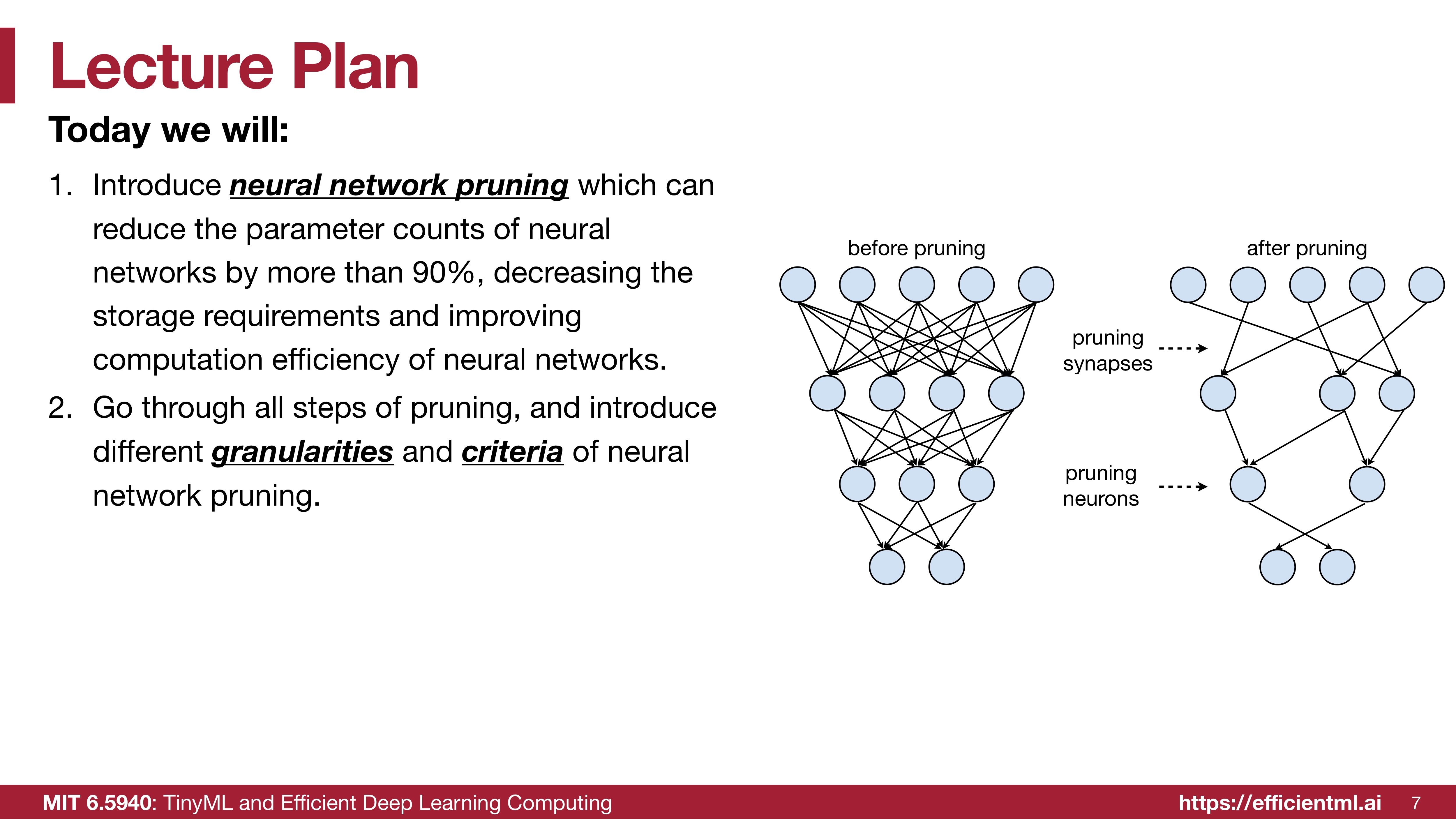
우리는 이 강의에서 Pruning에 대해서 학습할 것이다. Pruning(가지치기) 이란 neural network를 경량화할 때 사용하는 방법이다. 중요도가 낮은 파라미터는 제거하여 모델의 크기를 줄이고 계산의 효율성을 높인다. 위 슬라이드의 그림에서 가지치기가 된 모습을 시각적으로 이해할 수 있다.
granularities(입도)와 criteria(기준)으로 Pruning에 대해 알아볼 수 있다. 입도는 어떤 모양으로 가지치기를 할 것인지에 대한 내용이고, 기준은 어떤 것을 기준으로 가지치기를 할 것인지에 대한 내용이다. 어떤 모양과 어떤 기준으로 pruning을 하느냐에 따라 사이즈가 더 작아져도 모델의 성능이 더 좋아질 수 있다.

사람의 뇌에서도 Pruning이 일어난다고 한다. 그래프를 보면 유아기쯤 시냅스의 개수가 고점을 찍었다가 성장할 수록 일부가 줄어든다. 여기서 Pruning이 일어나는 것이다. 유아기 때 15000개의 시냅스가 있을 때보다 7000개의 시냅스가 있는 어른이 더 똑똑하다. AI 모델도 마찬가지이다. 시냅스의 수가 많다고 더 성능이 좋은 것이 아닌, 적절히 가지치기가 되었을 때 모델의 크기가 더 작으면서도 성능이 더 좋을 수 있다는 의미가 드러난다. 인간의 뇌에서 자연적으로 진행되는 pruning을 AI모델에도 그대로 적용하려는 것이 신기하다.
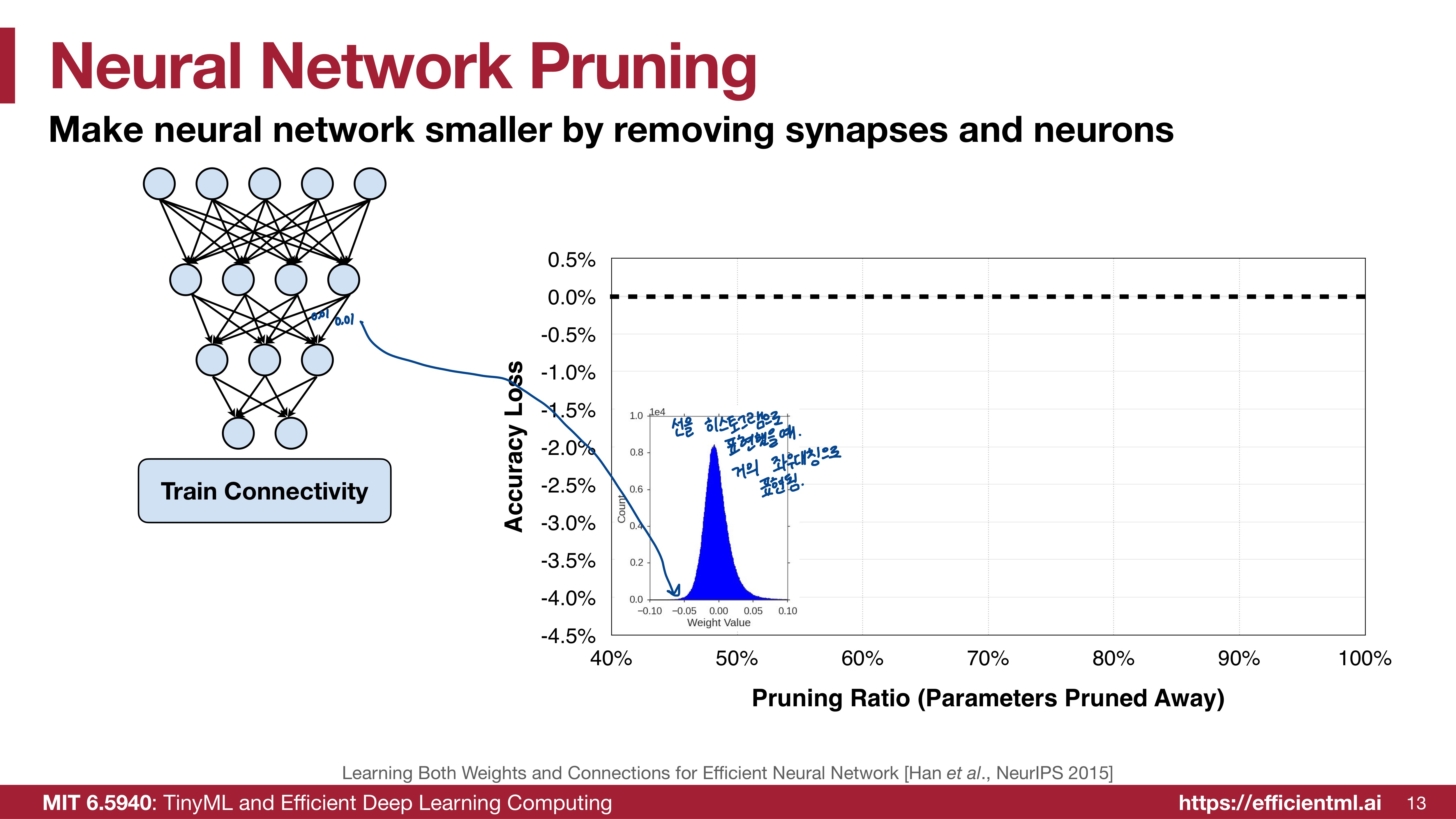
2015년에 송한교수님께서 진행하신 실험이다. 모델의 가중치들을 히스토그램으로 표현한 것이 파란색 그림이다. 어느정도 좌우대칭적인 분포를 가진다.
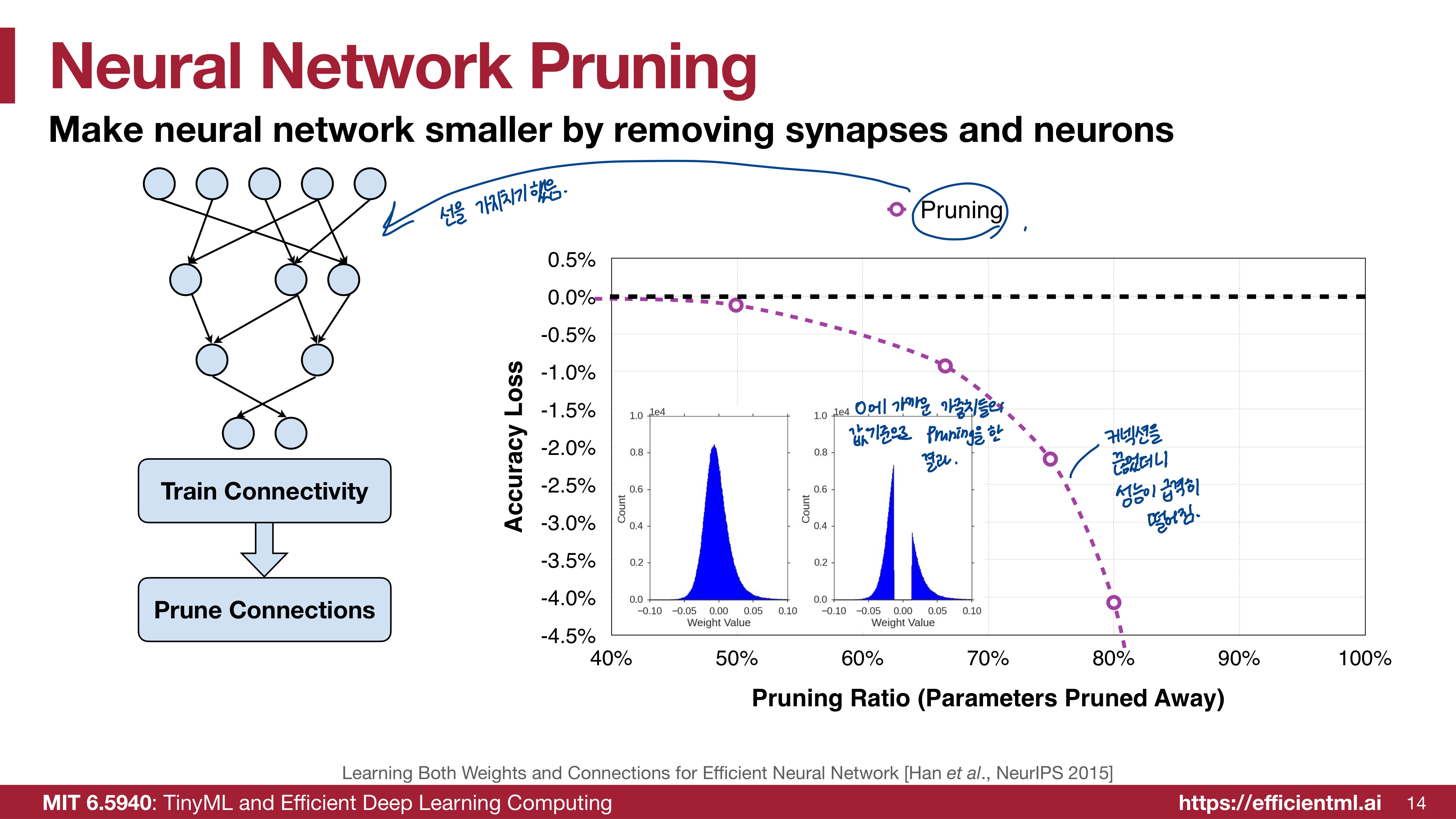
이때 0에 가까운 가중치들의 값을 기준으로 Pruning을 제거했다. 0에 가까운 가중치들을 제거한 이유는 0을 곱하면 0이므로 비교적 가중치의 중요도가 낮다고 판단해서일 것이다. 히스토그램에서는 0을 기준으로 근처 값들이 사라져 Pruning전과는 조금 다른 분포를 보인다. 성능도 급격히 떨어진다. 50%정도 Pruning을 진행했을 때는 원래의 모델과 큰 성능차이가 없었는데, 그 이후 급격히 떨어진다. 80%정도 Pruning을 진행하니 기존 모델과 성능차이가 매우 크게 나는 것을 그래프로 확인할 수 있다. 어쨌든 이런 성능이면 pruning을 사용할 수 없다.
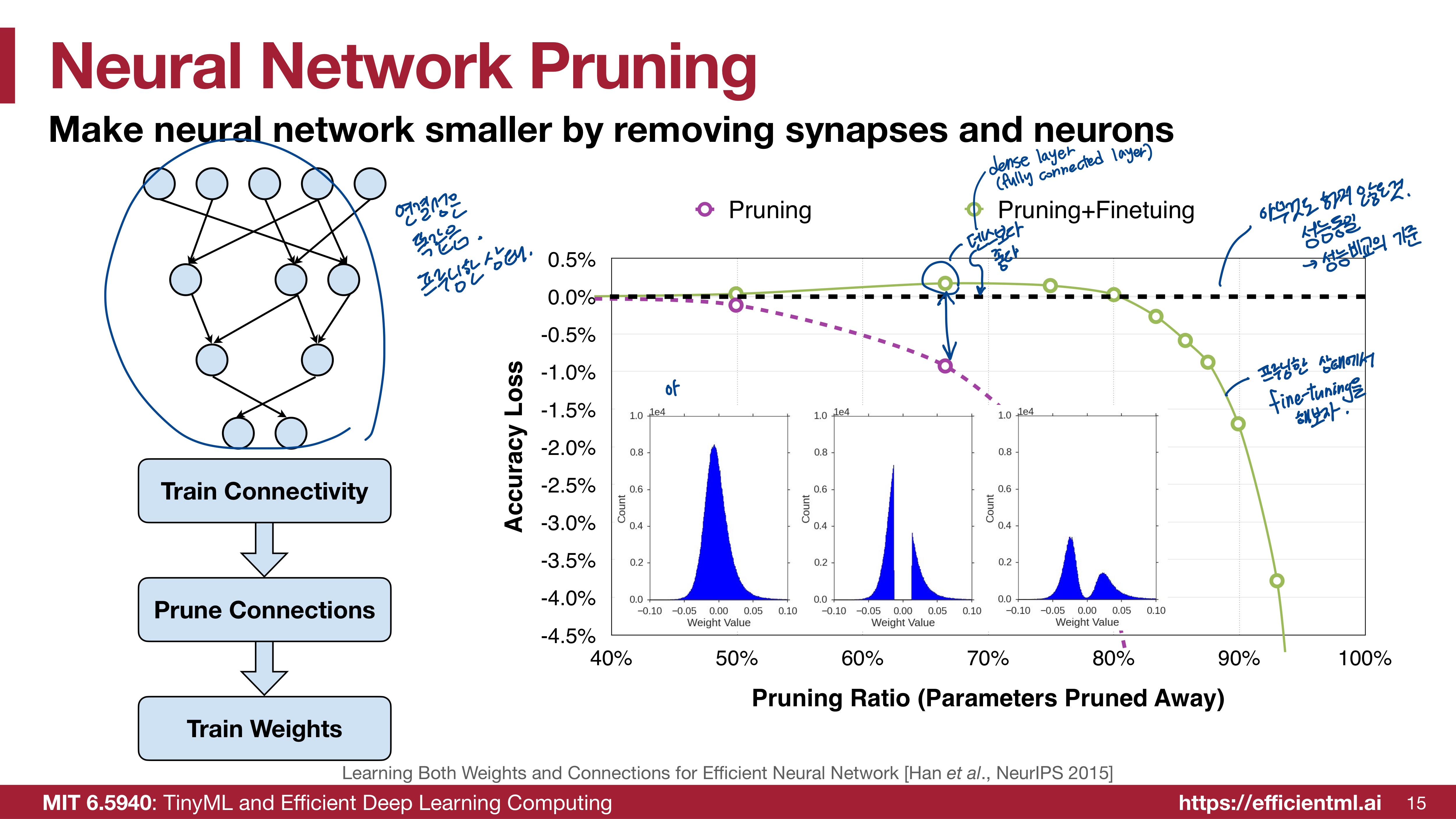
그렇다면 Pruning한 상태에서 Fine-tuning을 해보자. pruning을 한 상태인 것은 맞으므로 가중치들의 연결성은 똑같다. 가지치기되어있는 상태이다. 파란색 히스토그램을 보면 pruning을 진행한 히스토그램에서 분포는 비슷한데 fine-tuning을 진행했으므로 둥글둥글해졌다. 성능은 오히려 아무것도 하지 않은 원상태의 모델보다 좋아지는 부분도 있다. 80% pruning을 진행한 지점쯤부터는 성능이 급격히 떨어진다.

그렇다면! Pruning과 Fine-tuning을 반복해보자. pruning을 하고 fine-tuning을 하고, 다시 pruning, 그리고 fine-tuning을 한다. 이를 Iterative Pruning and Finetuning이라고 하여 빨간 색 그래프로 표시했다. 이는 90% Pruning 지점까지도 성능이 원래의 모델과 동일하다. 많은 횟수의 pruning을 진행했으므로 모델의 크기는 훨씬 감소했을텐데 동일한 성능을 낸다니, 매우 의미있는 결과이다.

여러 모델에 대해 pruning을 진행해본 결과이다. 정도는 다르지만 모든 모델들이 pruning을 진행한 후 모델의 크기가 크게 감소했다. 가장 오른쪽 열인 MACs는 Multiply Accumulated Computation으로 연산량의 지표이다. 연산량도 많이 줄어든 것을 확인할 수 있다. 하지만 모델의 크기가 감소한 것과 연산량의 감소가 비례하지는 않는다.

Pruning을 진행한 모델으로 생성한 이미지이다. 90% Pruning을 진행했음에도 이미지 품질의 저하는 거의 없었다고 한다.

pruning을 하지 않은 상태에서는 Loss가 최소가 되는 weight를 찾는 것이 모델 최적화의 목표였지만, pruning까지 진행한다면 조건부 최적화를 목표로 한다. 0이 아닌 weight의 개수가 N보다 작을 때, Loss가 최소가 되어야 한다.

이제 Pruning Granularity, 즉 입도에 대해 알아보자. 어떤 모양으로 가지치기를 할 것인지에 대한 것인데, 크게 structured와 non-structured가 있다.
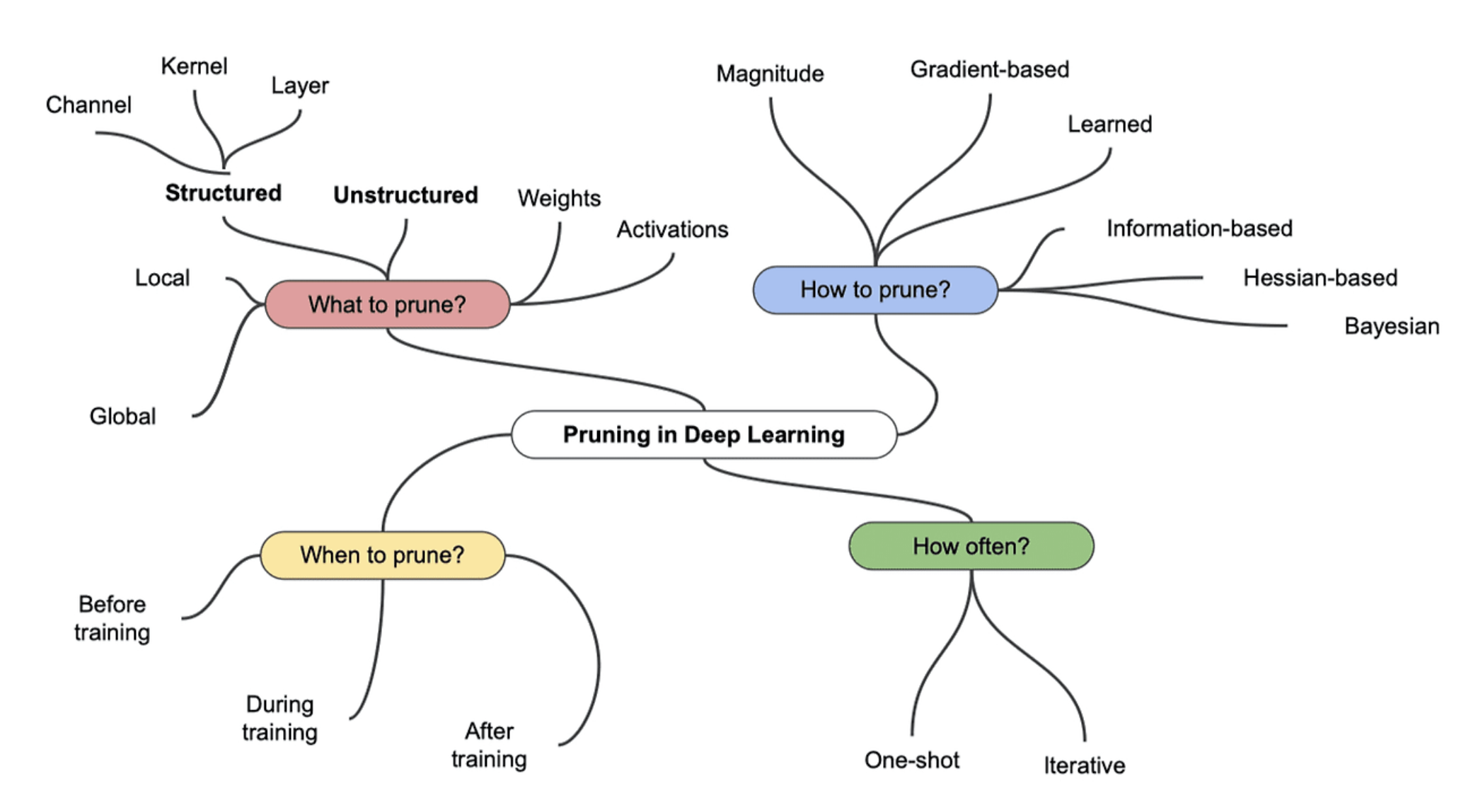
이 자료가 pruning을 한 눈에 설명해준다. 먼저 Structured와 Unstructured는 What to prune?에 속한다. 두 개는 각각 장단점이 있다.
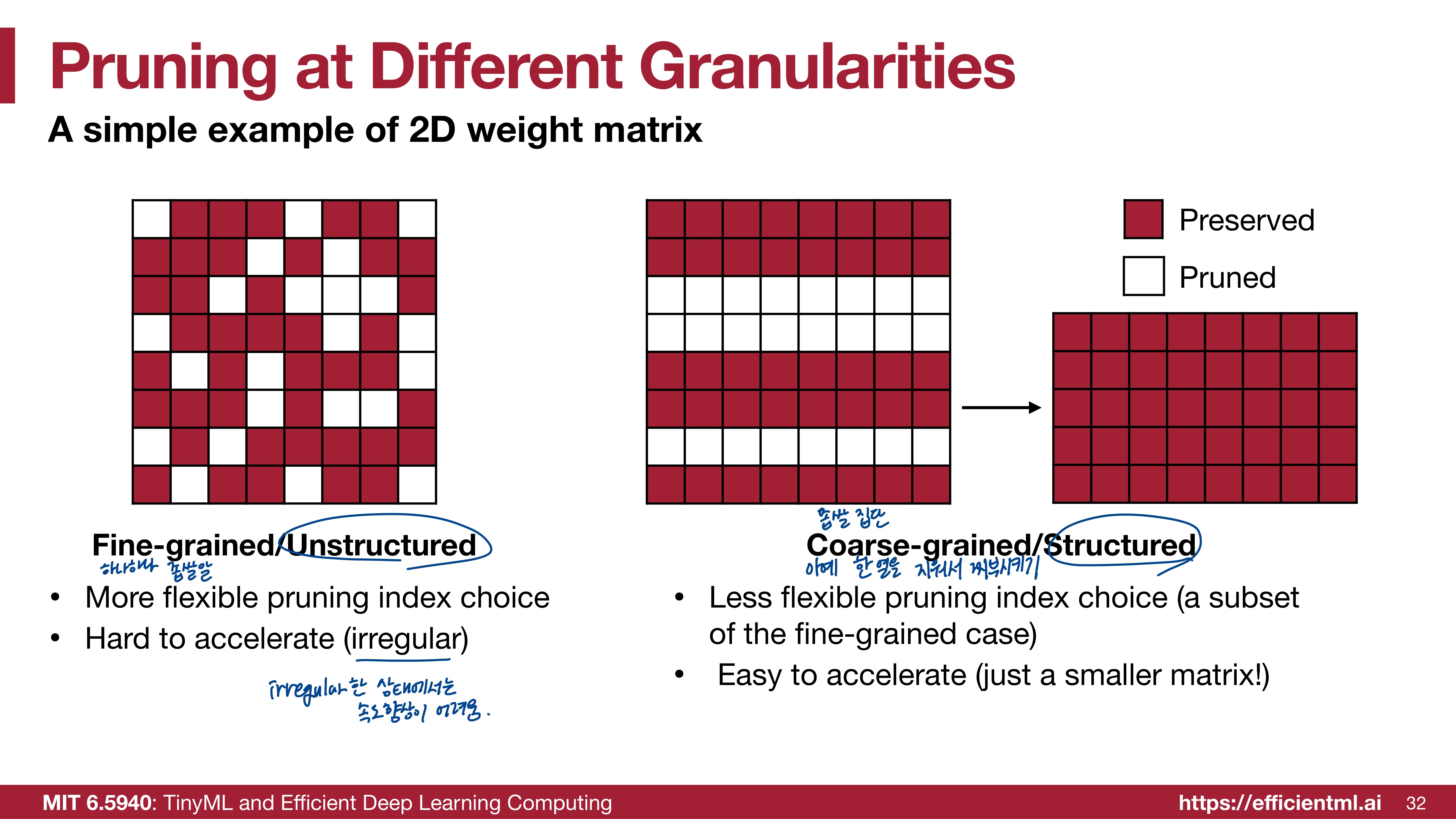
1. Fine-grained / Unstructured
- 불규칙하게 각 가중치를 Pruning한다.
- 특정 패턴이나 규칙에 얽매이지 않고 불규칙하게 Pruning을 하므로 개별 가중치를 자유롭게 선택하여 제거할 수 있다는 점에서 유연성이 좋다. 정밀하게 조정할 수 있다.
- 불규칙적이므로 처리 속도가 느릴 수 있고 속도 향상이 어렵다.
2. Coarse-grained / Structured
- 블록이나 행 단위로 가중치를 Pruning한다.
- 행, 열, 또는 블록 단위로 Pruning을 해야하므로 Pruning을 할 때 선택의 폭이 제한된다. 유연성이 떨어진다. 정밀한 조정이 어렵다.
- Pruning 후에 매트릭스가 더 작은 형태로 정형화될 수 있어 가속화가 용이하다.
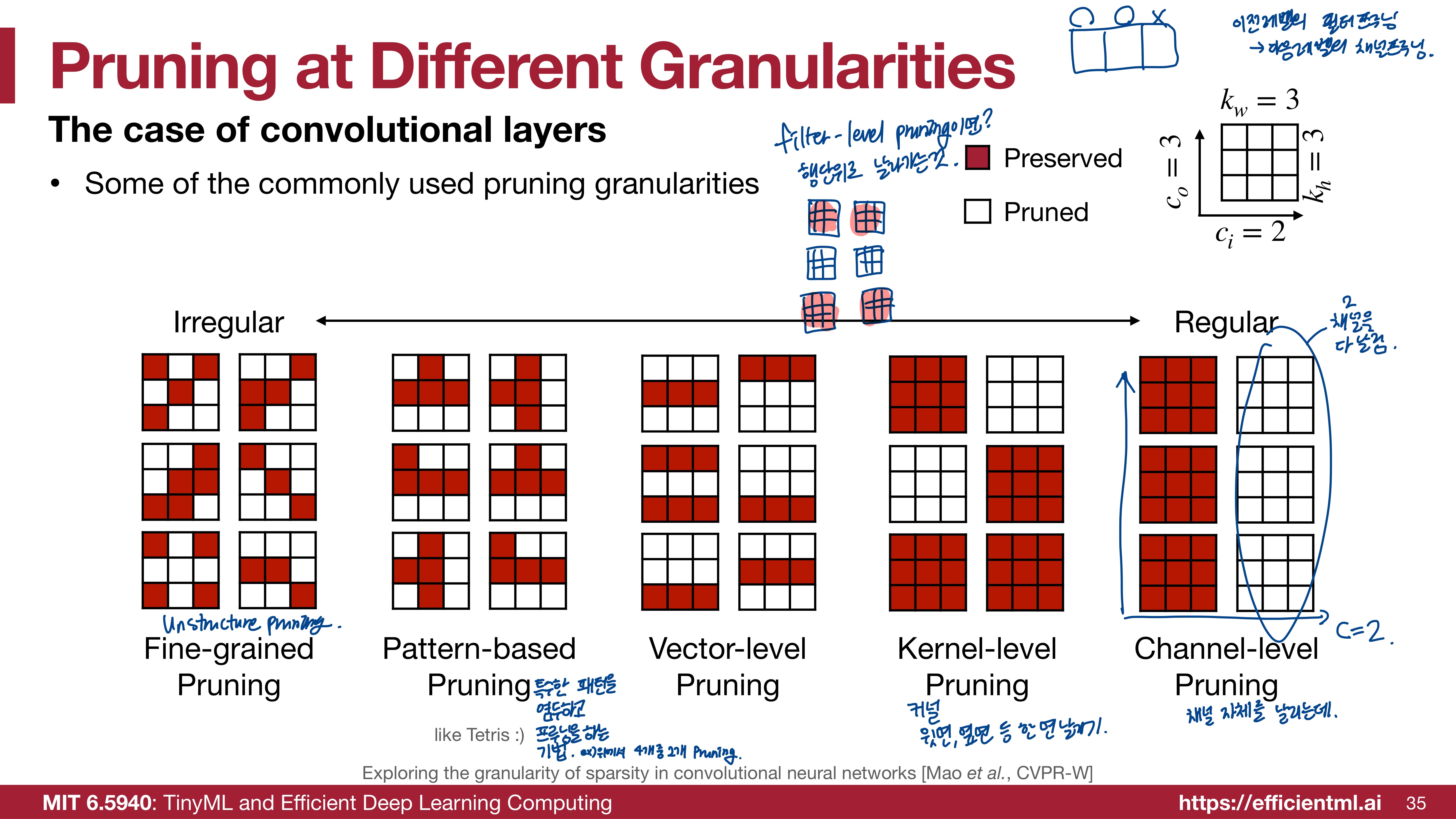
convolutional layers에서는 granularities에 따라 위와 같은 방식으로 pruning을 할 수 있다. 좌측부터 가장 불규칙한 순으로 나열되어 있고 가장 규칙적인 pruning은 채널 단위 Pruning이다.
- CNN(Convolutional Neural Network)에서 채널(Channel)은 필터(혹은 커널)의 출력이다. 예를 들어 이미지에서 R,G,B 각 채널이 있듯이 필터는 여러 채널을 사용해 이미지를 처리한다. 채널 단위 Pruning을 보면 하나의 채널 전체가 삭제된 것을 확인할 수 있다. 정보가 크게 손실될 수 있지만 모델 크기와 계산량을 줄이는 데에는 효과적이다.
- 커널(Kernel)은 컨볼루션 연산을 수행하는 작은 크기의 행렬이다. 이미지나 피처맵을 슬라이딩하면서 특징을 추출하는 역할을 한다. 커널 단위로 Pruning을 하면 위와 같은 그림처럼 가지치기될 수 있겠다.
(* 필터는 하나 이상의 커널로 구성된 덩어리이다. 여러 개의 커널이 합쳐져서 하나의 필터를 구성한다.) - Vector 단위 프루닝을 하면 가중치 행렬 내에서 일부 열 또는 행이 제거된다.
- Pattern-based Pruning은 특수한 패턴을 염두하고 프루닝을 하는 기법이다. N:M sparsity는 M개의 연속된 뉴런이 있을 때 N개를 Pruning하는 것이다. 아래 이미지에서 더 자세히 확인할 수 있다. 2:4 프루닝의 경우 아래 그림처럼 4개 중에 2개가 제거된 형태를 띈다. 어느정도의 규칙성을 가지게 되어 Unstructured pruning에서의 병렬처리나 하드웨어 가속에 적합하지 않았던 문제가 보완된다.


(이어서 작성 예정)