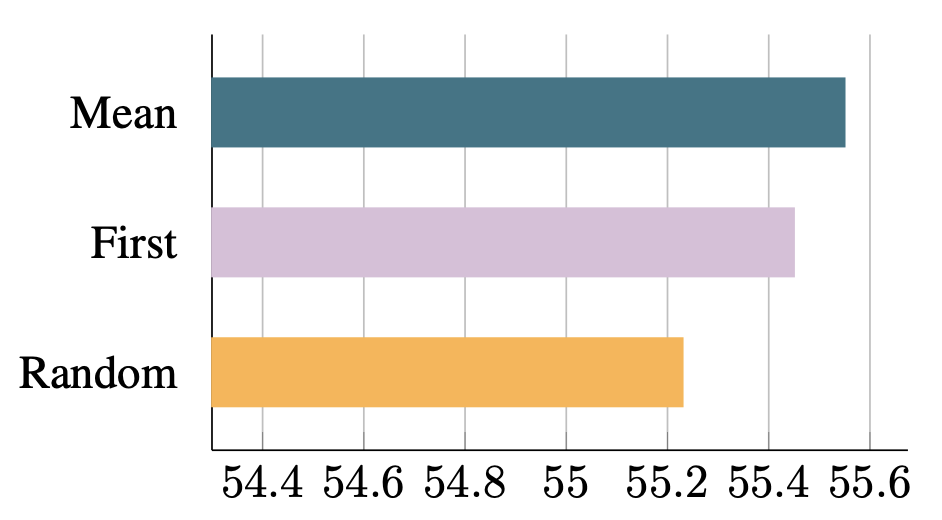Multi-Query Attention(MQA)는 Self-attention의 병렬성을 높여 디코더의 추론 속도를 높였지만 성능 저하 문제가 발생할 수 있었다.
Autoregressive 디코더 추론에서는 Transformer모델에 심각한 병목현상을 일으킨다. Autoregressive하다는 것은 이전의 예측을 바탕으로 다음 스텝에 하나의 토큰을 예측하는 것이다. 따라서 모든 스텝마다 매번 디코더 가중치와 attetnion key, value를 로드해야 한다. 이 과정에서 메모리 대역폭 오버헤드가 발생해 병목현상이 일어나는 것이다. 그래서 Multi-Query Attention(MQA)가 등장했다. MQA는 매번 Key, Value를 로드해야 하는 문제를 막고자 단일 Key,Value를 여러 개의 Query head에 사용하는 방식이다. 하나의 Key, Value를 공유하여 사용하므로 메모리 대역폭을 엄청나게 줄일 수 있지만 성능 저하와 학습 불안정성으로 이어지는 문제가 발생한다. 또한 MQA를 사용하는 언어모델도 있지만(PaLM), 모든 모델에서 채택된 기술은 아니다. T5나 LLaMA 등의 모델에서는 MQA를 사용하지 않는다.
따라서 본 논문에서는 이러한 문제점들을 해결하기 위해 두 가지 방안을 제시한다. 첫 번째는 Multi-Head Attention이 있는 언어 모델 체크포인트가 업트레이닝 될 수 있는 것이다. 그리고 두 번째는 Grouped-Query Attention(GQA)이다. 하나씩 알아보도록 하자
2. Method
2.1. Uptraining
Multi-head 모델에서 Multi-query모델을 생성하는 과정은 두 단계로 이루어진다. 1. 체크포인트 변환 2. 모델이 새로운 구조에 적용되도록 추가적인 pre-training을 적용한다.
위 이미지는 Multi-head 체크포인트 에서 Mutli-Query 체크포인트으로 변환하는 과정을 보여준다. 이미지의 왼쪽을 보면 각 head마다 Key 투영 행렬이 있다. 이 행렬들을 mean pooling을 통해 하나의 단일 Key 투영 행렬으로 통합하는 것이다. Mean pooling 방식은 하나의 Key 및 Value를 선택하거나 랜덤으로 Key, Value를 초기화하는 것보다 더 잘 작동한다.
* Mean pooling 여러 개의 값을 하나로 합치기 위해 평균값을 계산하는 방법이다. 여러 정보를 통합하면서도 정보 손실을 줄이고 정보의 균형을 유지할 수 있도록 하기 위해 mean pooling을 사용한다.
2.2 Grouped-Query Attention
GQA에서는 query head를 G개의 그룹으로 나눈다. 각각의 그룹은 하나의 Key head와 Value head를 공유한다. GQA-g에서 g부분에 그룹의 수를 표기하는데, 그룹의 수가 1인 GQA-1은 하나의 그룹을 가진 것, 즉 MQA라고 할 수 있다. 그룹의 수를 head의 개수만큼 가진 GQA-h는 MHA와 같다. 이처럼 GQA는 하나의 새로운 개념이 아니라 MHA와 MQA의 보간과 같은 것이다. 위 이미지에서는 MHA, GQA, MQA를 시각적으로 비교해준다. Multi-head 체크포인트를 GQA 체크포인트로 변환할 때 mean pooling을 통해 각 그룹의 Key head와 Value head를 구성한다.
GQA를 통해 그룹의 수를 1에서 head개 사이로 조정했을 경우 MHA보다는 빠르면서도 MQA보다 성능이 좋다. 성능과 시간과의 trade-off 속 중간 지점의 역할을 해주는 것이다. MHA에서 MQA로 바뀌면서 H개의 Key head, Value head를 한 개의 Key head, Value head로 줄어드므로, 그만큼의 key-value 캐시도 줄어들고 로드해야하는 데이터의 양도 H만큼 줄어든다. 그러나 큰 모델일수록 더 많은 Key, Value head를 사용하는데, MQA는 모든 헤드를 하나로 줄여버리기 때문에 지나치게 메모리와 대역폭이 줄어들어 정보 손실이 커지고 성능 저하가 발생할 수 있다. GQA를 사용하면 모델 크기가 증가함에 따라 메모리와 대역폭이 비례적으로 감소하게 할 수 있다. 이 외에도 몇 가지 이유들로 GQA는 특히 큰 모델에 대해 좋은 trade-off를 제공할 수 있다.
3. Experiments
3.1 Experimental setup
3.2 Main results
위 이미지는 추론 task에서 시간과 평균 성능을 비교한 표이다. MQA-XXL모델이 MHA-Large 모델보다 더 좋은 trade-off를 낸다. 성능은 더 좋으면서도 빠르다. GQA는 MHA-XXL과 성능은 비슷하면서 MQA와 속도가 비슷하다.
3.3 Ablations
- Checkpoint conversion
체크포인트 변환에 사용되는 방법들의 비교이다. Mean pooling이 가장 잘 작동했다. 직관적으로 모델에서 정보가 잘 보존되는 정도의 순서대로 좋은 결과가 나왔다.
- Uptraining steps
α가 약 0.1일 때 성능이 가장 좋다. α는 모델을 기존 데이터와 추가 데이터의 비율에 따라 학습시킬 때 얼마나 많은 비율의 추가 학습이 이루어졌는지를 나타내는 파라미터이다. α = 0은 업트레이닝이 전혀 이루어지지 않은 상태, 즉 기존 모델의 성능을 의미한다. α가 증가할수록 추가적으로 학습된 데이터의 비중이 높아지는 것을 의미한다.
- Number of groups
그룹의 수가 8개일 때까지는 오버헤드가 크지 않지만 더 많은 그룹일 때는 오버헤드가 많이 발생한다.
찬찬히 읽다보니 이해가 잘 갔다. 다른 블로그 글도 많이 보면서 공부를 했는데 공부하던 중 다른 블로그에서 그래프를 잘못 해석한 것도 찾았다. 무조건 받아들이지 않고 이해하면서 공부하고 있는 것 같아 뿌듯했다. 예전에 배웠던 transformer와 attention도 복기되어 좋았다.