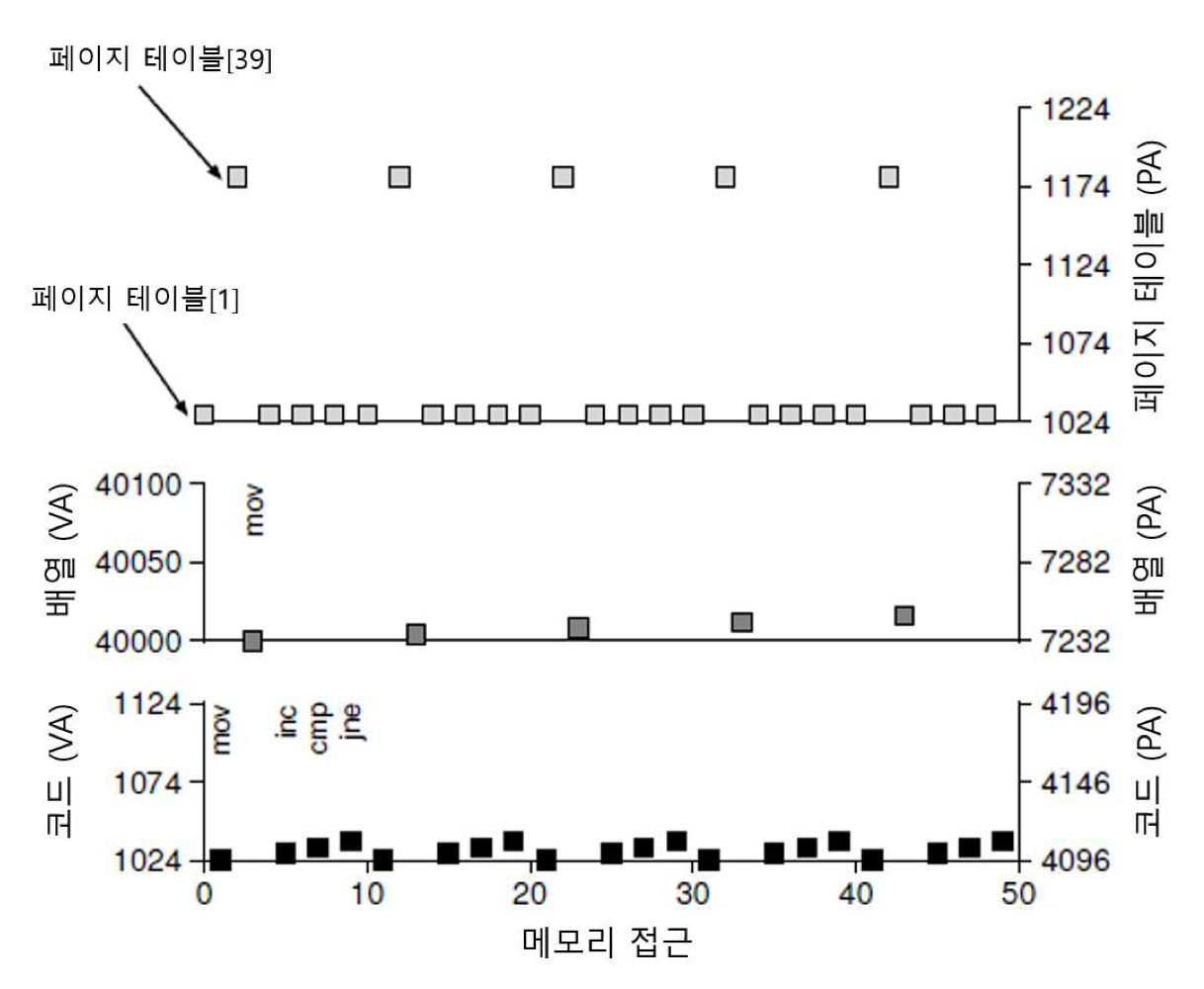
핵심 질문: 주소 변환 속도를 어떻게 향상할까? 🔹 흐름 정리 지난 블로깅에서 페이징 기법에 대해 알아보았다. 페이징은 프로세스 주소 공간을 작은 고정된 크기(page)로 나누고, 각 페이지의 실제 위치를 메모리에 저장한다. 매핑 정보를 저장하는 자료 구조를 페이지 테이블이라 한다. 매핑 정보 저장을 위해서는 더 큰 메모리 공간이 요구된다. 그런데 여기서 문제가 생겼었다. 가상 주소에서 물리 주소로의 주소 변환을 하려면 메모리에 존재하는 매핑 정보를 읽어야 한다. 모든 load/store 명령어 실행이 추가적인 메모리 읽기를 수반하는 것이다. 이 문제를 해결하기 위해서 하드웨어의 도움을 받는다. TLB에 대해 알아보자. 🔹 TLB란? TLB는 Translation-lookaside buffer의 약자로 ..