MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
https://arxiv.org/abs/2402.14905
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
This paper addresses the growing need for efficient large language models (LLMs) on mobile devices, driven by increasing cloud costs and latency concerns. We focus on designing top-quality LLMs with fewer than a billion parameters, a practical choice for m
arxiv.org
Meta에서 On-Device 애플리케이션을 위해 최적화된 소형언어모델 'MobileLLM'을 공개했다. 2024년 2월에 처음 출간되어 2024년 6월에 마지막으로 수정된 최신 논문이다.
Abstract
클라우드 비용 증가와 지연 문제로 인해 효율적인 LLMs에 대한 필요성이 커지고 있는 가운데 저자는 10억개 미만의 파라미터를 가지면서 높은 품질의 LLMs을 설계하는데 중점을 두었다. 데이터의 양과 파라미터 수가 모델 품질을 결정하는 핵심 요소라는 편견에서 벗어나 10억개 미만의 규모를 가진 LLMs의 아키텍처 중요성을 강조한다.
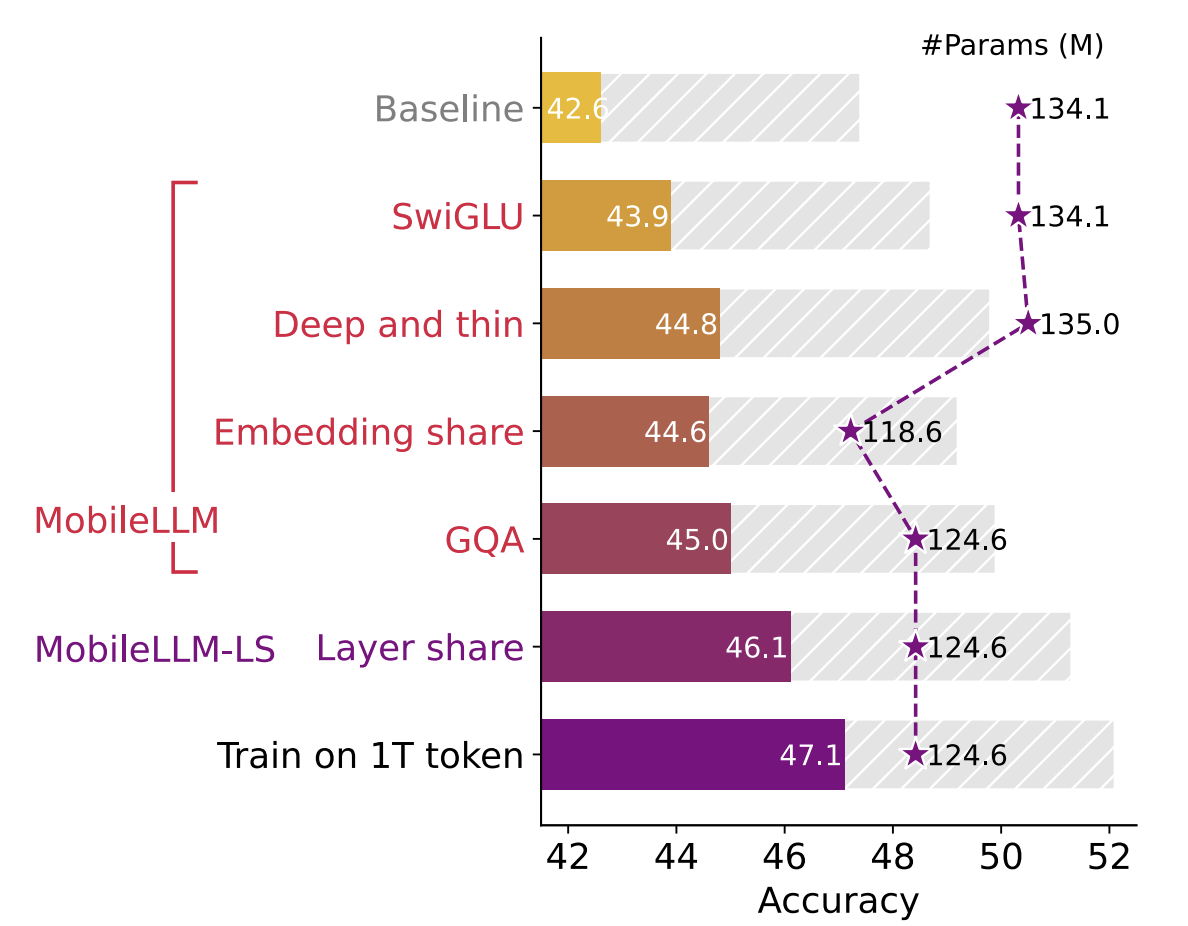
깊고 얇은 구조(Deep and thin architectures), 임베딩 공유(Embedding Sharing), 그룹 쿼리 어텐션(Grouped-query attention mechanisms)을 활용해서 "Mobile LLM"의 기본 네트워크를 구축했다. 이는 125M/350M 규모의 모델에 비해 2.7%/4.3%의 정확도 향상을 달성했다.
여기서 모델의 크기 증가 없이 블록 단위의 즉시 가중치 공유 방법(immediate block-wise weightsharing approach)을 제안하여 지연이 거의 발생하지 않도록 하였다. 그 결과로 나온 "Mobile LLM-LS"모델은 "Mobile LLM" 125M/350M에 비해 추가적으로 0.7%/0.8%의 정확도 향상을 보여주었다.
Mobile LLM은 기존 10억 개 미만 파라미터를 가진 모델과 비교했을 때 chat benchmarks에서 상당한 개선을 보였고, API 호출 작업에서 LLaMA-v2 7B 모델과 유사한 정확성을 보여주었다.
모델의 크기가 작음에도 일반적인 On-Device에 충분히 사용할 수 있음을 보여준다.
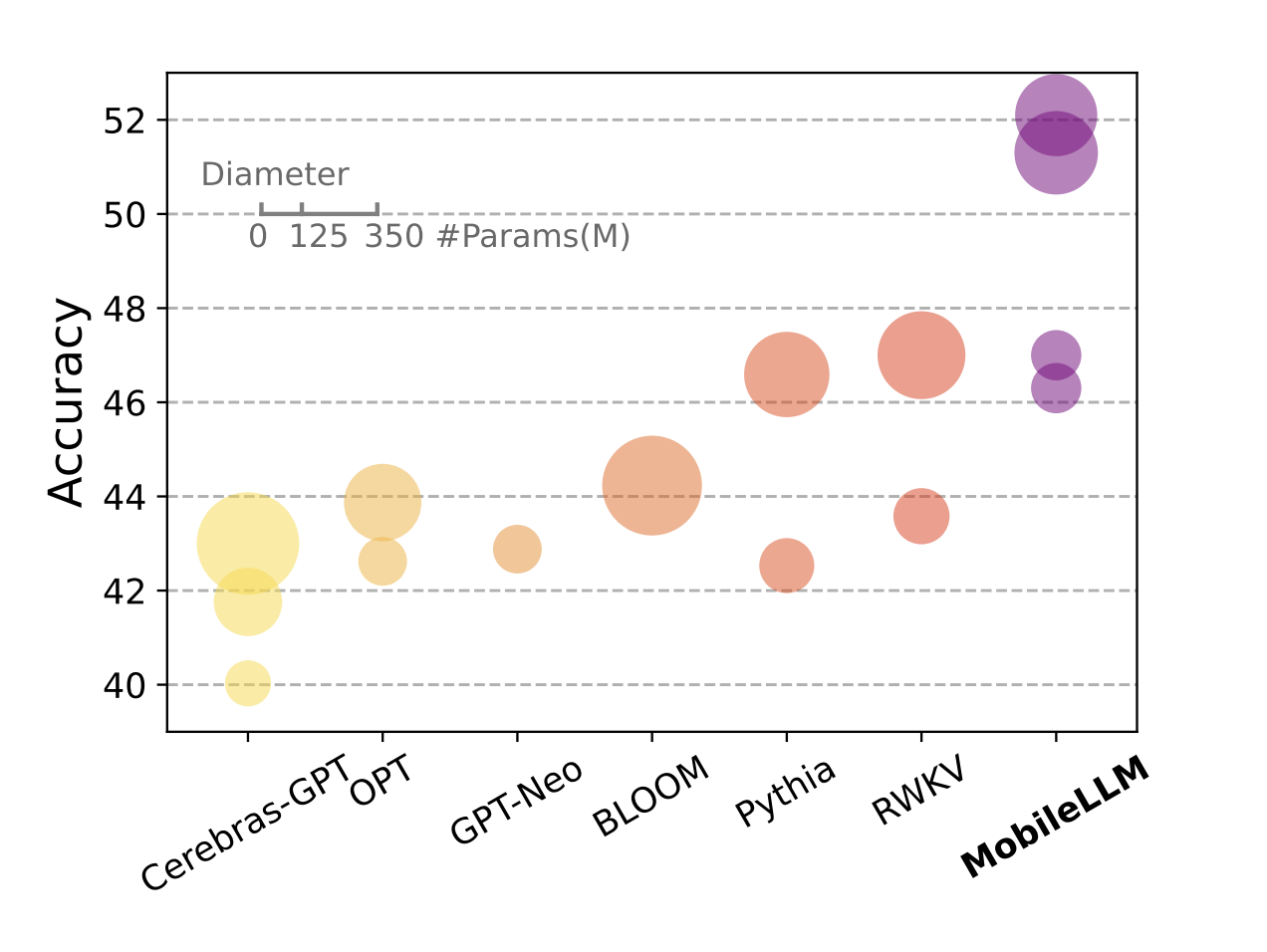
모델의 크기에 따른 성능 차이를 시각적으로 보여주는 그림이다. MobileLLM의 경우 모델의 크기가 매우 작음에도 다른 대형 언어모델만큼의 성능을 보여준다.
1. Introduction
Large Language Models(LLMs)는 일상에 스며들고 있다. 미래에는 LLM에 대한 의존도가 더 높아질 것으로 예상되는데, 이에 따라 처리 성능 요구가 커질 것이고 대규모 연산 자원이 필요해진다. 이는 클라우드 비용 증가와 에너지 소비 문제(이산화탄소 배출량)로 이어질 수 있다.
또한 모바일 기기에서 LLM을 사용하기에는 용량과 에너지 소비량의 한계점이 있다.
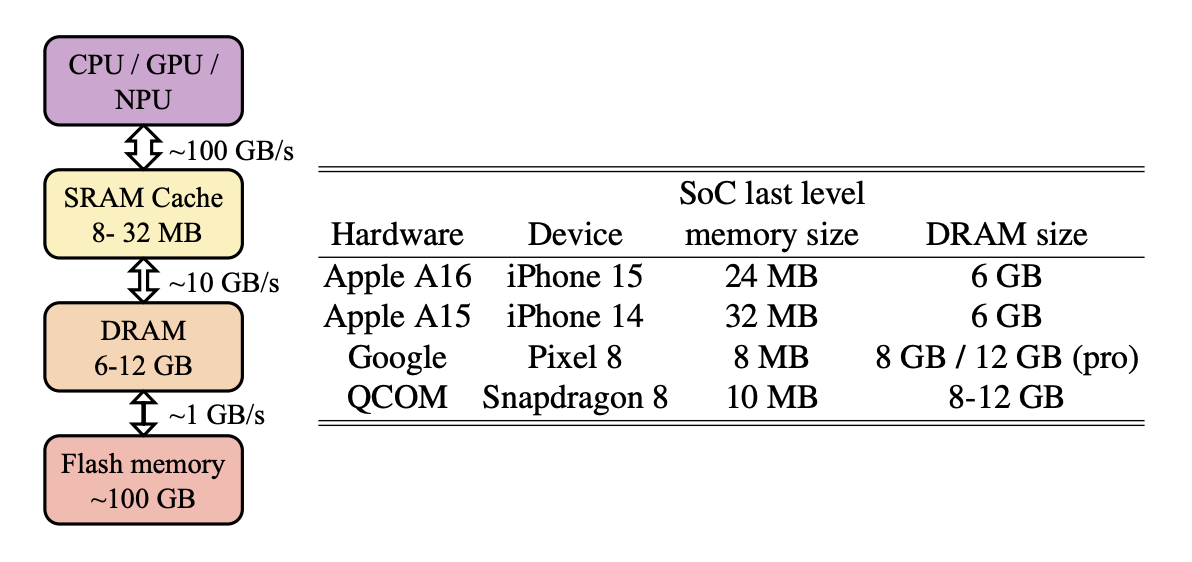
현재 모바일 기술에서의 DRAM 크기를 고려할 때 LLM을 도입하기 어렵다. LLaMAv2 7B 모델과 같은 대형 LLM을 넣어야 하지만, 현재 아이폰 15는 6GB의 DRAM 용량을 가지고 있다. DRAM은 운영체제와 다른 애플리케이션들과 공유되기 떄문에 모바일앱은 DRAM의 10% 이상을 사용해서는 안된다. 따라서 모바일 기기에서 사용하기 위한 LLM은 10억 개 미만의 파라미터를 가진 작은 크기여야 한다. (8비트 양자화 가중치를 사용할 경우 10억 개 파라미터 모델은 약 1GB의 메모리 용량을 차지할 것이다.) 모바일 기기가 가지고 있는 에너지를 고려할 때 LLM의 에너지 소비도 고려해야 한다.
2. Improving Sub-billion Scale LLM Design
- 모델 디자인 기술
1) SwiGLU FFN 사용: Feed-Forward Network에 SwiGLU 활성화 함수를 적용
2) Lanky(deep and thin) Architecture: 모델이 깊고 얇은 구조를 가지도록 설계하여 효율성 증가
3) Embedding Sharing Method 재검토: 파라미터 재사용을 통해 메모리 사용 최적화
4) Grouped Query Attention 활용: 그룹화된 쿼리 어텐션 메커니즘을 사용하여 효율적인 정보 처리를 구현한다. - 모델 개선( -> MobileLLM-LS)
Block-wise Layer Sharing: 모델의 레이어를 공유하는 새로운 방법을 개발하여 정확도 추가 향상, 메모리 오버헤드 발생시키지 않고 지연(latency) 오버헤드만 약간 발생시킴.
2) Lanky(deep and thin) Architecture
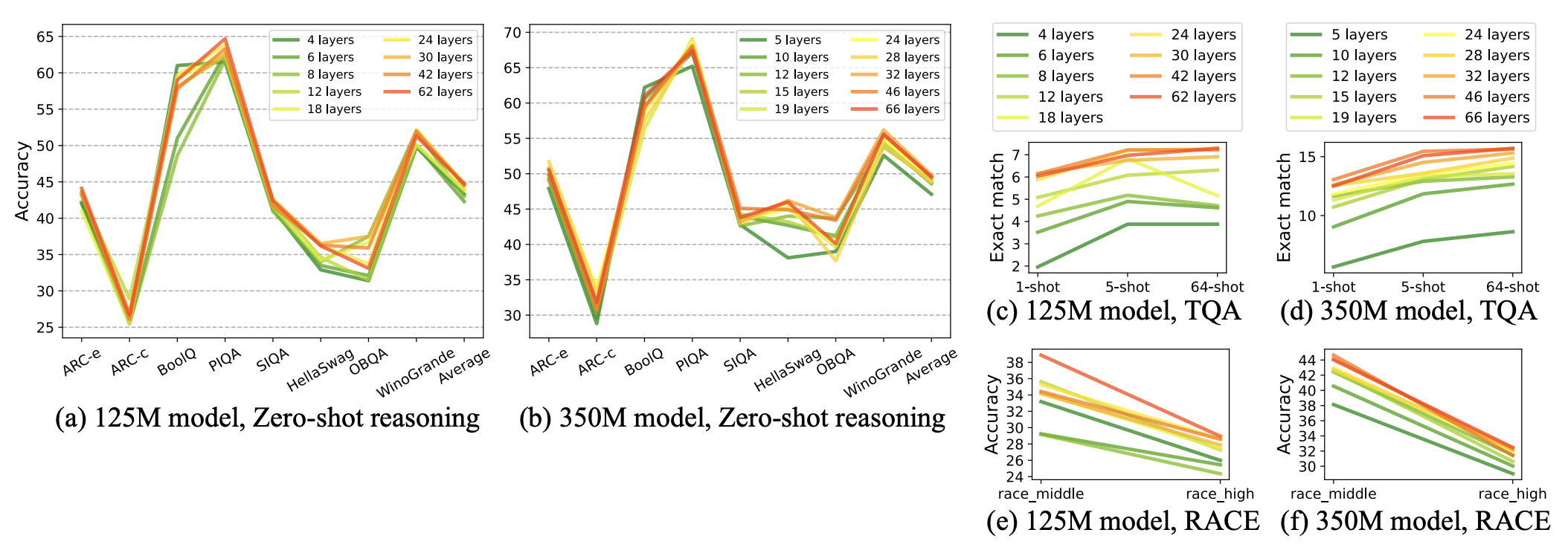
비슷한 크기의 모델에서 깊이가 깊고 얇은 모델의 성능이 더 좋다는 것을 보여주는 실험 결과
"깊고 얇은" 구조 = 더 많은 레이어를 가지면서 각 레이어의 뉴런 수는 더 적은 경우를 말한다. 각 레이어에서 처리할 수 있는 정보의 양은 적지만 여러 층을 통해 복잡한 패턴을 학습할 수 있다.
3) Embedding Sharing Method

임베딩 층의 비율이 작은 대형 모델에서는 임베딩 공유의 효과가 적어 LLM에서는 사용되지 않았으나 소형 모델에서는 효과적이다. 입출력 임베딩을 공유하여 파라미터 수를 크게 줄일 수 있다.
4) GQA(Grouped Query Attention) 활용
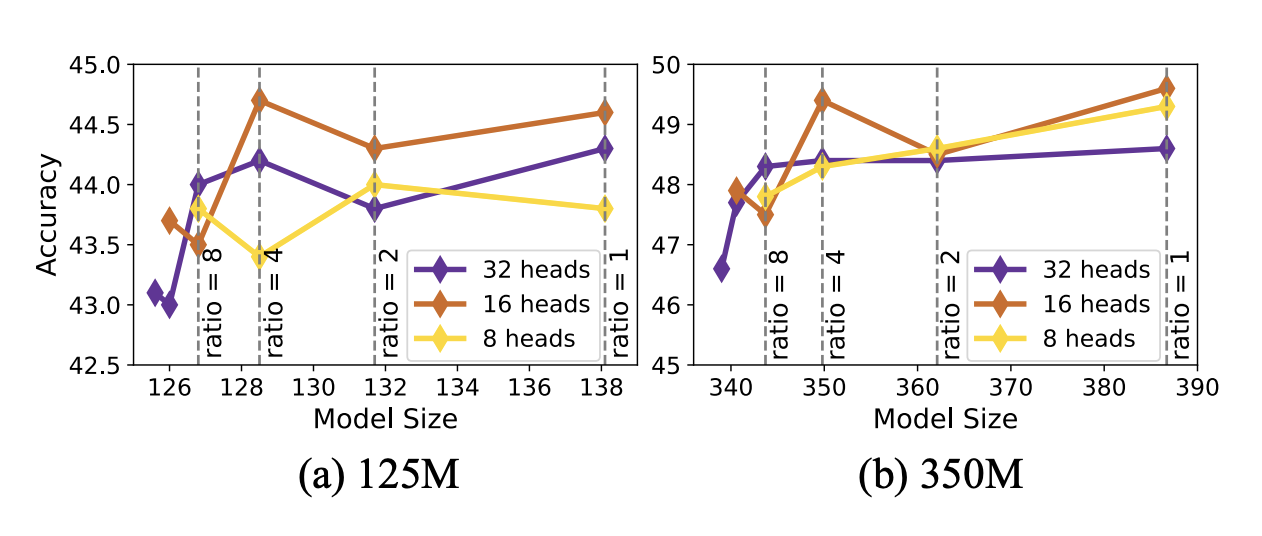
실험적으로 헤드 수를 최적화했으며(16개), GQA를 사용했다.
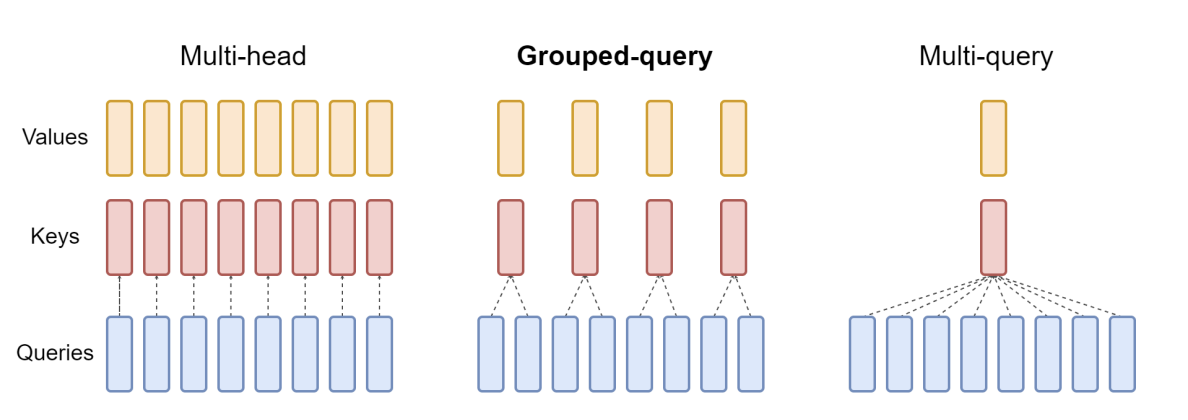
GQA(Grouped Query Attention)이란 query head를 G개의 그룹으로 나누고, 각 그룹은 하나의 key 및 value head를 공유한다. 위의 그림을 통해 직관적으로 이해해보면 쿼리 헤드 수에 비해 키, 밸류 헤드 수를 줄였고 같은 키, 밸류 헤드를 반복하여 사용해 어텐션 점수와 출력을 계산한다. 키, 밸류 헤드의 수를 줄여 파라미터 수를 줄이면서도 모델의 성능을 유지하거나 향상시킬 수 있다. GQA를 통해 모델의 파라미터 수를 줄이면서도 임베딩 차원을 증가시켜 모델 크기를 유지하면서 성능을 향상시켰다고 한다.
GQA 논문은 아래의 링크에서 확인할 수 있다.
https://arxiv.org/abs/2305.13245
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Multi-query attention (MQA), which only uses a single key-value head, drastically speeds up decoder inference. However, MQA can lead to quality degradation, and moreover it may not be desirable to train a separate model just for faster inference. We (1) pr
arxiv.org
+ Block-wise Layer Sharing
소형 모델에서는 깊고 얇은 구조가 유리하므로 layer를 늘려야 하는데, 용량의 크기는 커지면 안될 것이다. 그래서 추가 파라미터 없이 layer를 늘리기 위해 layer 공유를 통해 모델 정확도를 향상시켰다. 레이어 공유를 하면 모델 구조를 변경하거나 크기를 늘리지 않고서도 성능을 개선할 수 있다. 아래의 표는 여러 레이어 공유 방법 별 성능이다.


(d) Repeat-all-over-share가 가장 성능이 높았으나 하드웨어(모바일 기기)를 고려할 때 즉시 2번 계산하여 SRAM과 DRAM 사이의 메모리 전송을 최적화할 수 있는 Immediate block-wise share가 채택되었다.
3. Experiments
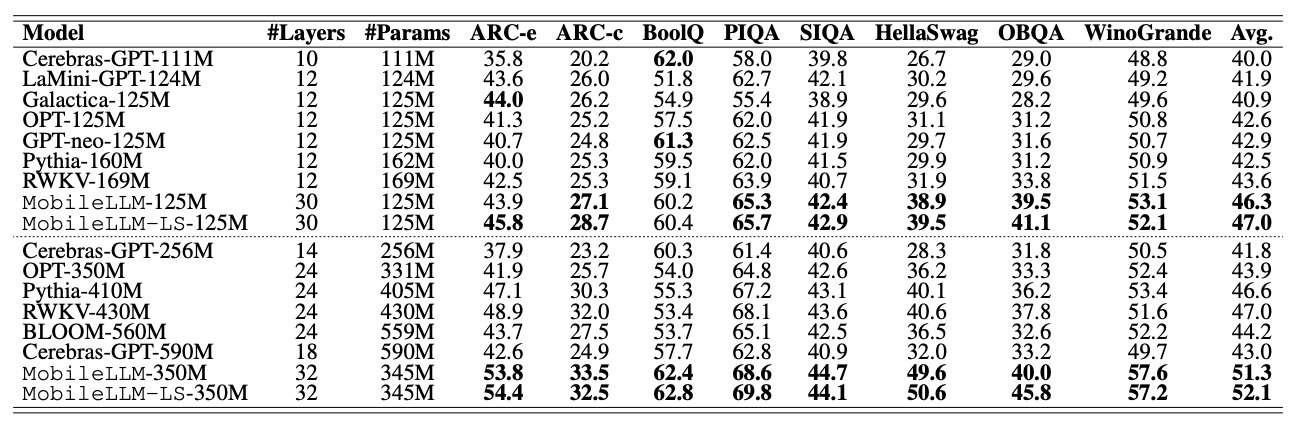
위의 표는 Mobile LLM과 최신의 10억개 미만 파라미터를 가진 모델들과의 비교를 보여준다. 모바일 내에서 실행될 수 있도록 최적화되었으면서도 대부분의 지표에서 다른 모델들과 동등하거나 더 좋은 성능을 보여준다.
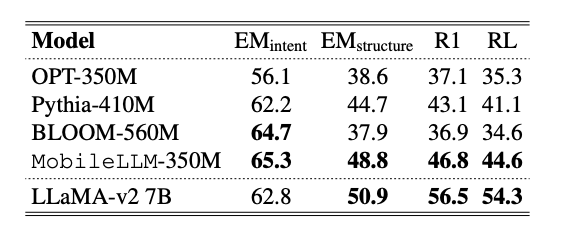
또한 Chat이나 API 호출 같은 downstream task에 대해서도 뛰어난 성능을 보였다.

양자화를 통해 메모리 효율성을 높이면서도 성능 저하는 미미하게 발생했다. MobileLLM은 양자화 적용에 매우 적합하며 레이어 공유 기법을 사용한 경우에도 양자화 호환성이 뛰어나다.
지식 증류(Knowledge distillation. KD)란 대형 모델(teacher model)의 지식을 소형 모델(student model)에 전이하여 소형 모델을 향상시키는 기법이다. LLaMA-v2 7B을 교사 모델로 사용하여 지식 증류 기법도 사용하려는 시도를 했다. next token prediction을 사용해서 대형 모델이 생성한 예측 결과를 소형 모델의 학습에 활용하는 방식으로 했다. 하지만 훈련 시간이 2~3배 증가하는 것 대비 성능은 비슷하거나 낮았다고 한다.
4. Related Work
- Model Compression
- Small Model Design
- Neural Architecture Search
- Weight Sharing
- Efficient Attention and Implementation
5. Conclusion
디바이스 어플리케이션 내에서 실행될 수 있도록 10억 개 미만 파라미터 규모의 모델 최적화에 초점을 둔 연구이다. 작은 모델에 있어서 깊은 깊이가 모델의 성능을 향상시켰고, 고급 가중치 공유 기법(Embedding sharing, grouped query attention, block-wise weight sharing)을 통해 성능 향상을 보여주었다. MobileLLM은 zero-shot 상식 추론, 질의응답, 독해에서 SoTA 모델(State-of-the-Art model, 최고 수준의 모델)에 비해 상당한 성능 향상을 보였다. 또한 채팅과 API 호출 작업도 효율적으로 처리되었다.
논문을 읽으면서 디바이스 어플리케이션 내에서 언어모델이 최적화되어야 하는 방향, GQA, block-wise weight sharing, 지식 증류 기법(Knowledge distillation. KD), SoTA 모델 등에 대해 새로 알았다. 실험 환경이나 성능의 구체적인 수치, 기법의 자세한 원리 등 이해하지 못하고 넘어간 부분도 많지만 전반적인 흐름을 직관적으로 이해했다. 양자화에 대해서는 아직 배우지 않아 가볍게 넘어갔는데 공부한 후 다시 살펴보아야겠다. 이렇게 디바이스 최적화를 한 다른 언어모델에는 어떤 것이 있는지, 본 논문에서 다룬 MobileLLM과는 어떤 차이가 있는지 더 살펴보고 싶다. 논문을 읽어보는 것이 처음인데 직관적인 이해를 하는 수준으로 잘 마무리하여 만족스럽다. GPT의 번역과 다른 블로그들의 도움을 받았다.
'엣지컴퓨팅' 카테고리의 다른 글
| LLaMA2의 GQA 코드 살펴보기 (1) | 2024.10.30 |
|---|---|
| [논문 읽기] LLaMA: Open and Efficient Foundation Language Models (4) | 2024.10.14 |
| [논문읽기] GQA: Training Generalized Multi-Query Transformer Models fromMulti-Head Checkpoints (0) | 2024.10.07 |
| [논문 읽기] Gemma: Open Models Based on GeminiResearch and Technology (5) | 2024.09.25 |
| [MIT 6.5940] EfficientML.ai Lec03: Pruning and Sparsity (1) | 2024.09.18 |